AG Coder: A Reference Coding Agent Built on ActiveGraph
An open-source coding agent built on ActiveGraph: graph-native, event-sourced, and auditable by default. A reference for what a coding agent looks like when the runtime is the substrate, not a wrapper around an LLM loop.
- ag-coder
- coding-agent
- reference-app
- activegraph
- announcement
I've been building a set of reference applications to make ActiveGraph easier to understand.
ActiveGraph is a graph-native runtime for agents. That can sound abstract until you see it applied to familiar workflows, so I want the examples to be concrete: research agents, coding agents, memory systems, workflow agents, review agents, and other places where agent execution should be inspectable, replayable, and extensible.
AG Coder is one of those examples.
It is an open-source coding agent built on ActiveGraph. You give it a goal, it plans, reads files, calls a model, uses tools, proposes edits, runs commands, and records the whole process as a live causal graph.
The goal is not to build a Cursor replacement. The goal is to show what a coding agent looks like when the runtime is graph-native from the beginning.
What AG Coder is
AG Coder is a small web-based coding-agent cockpit.
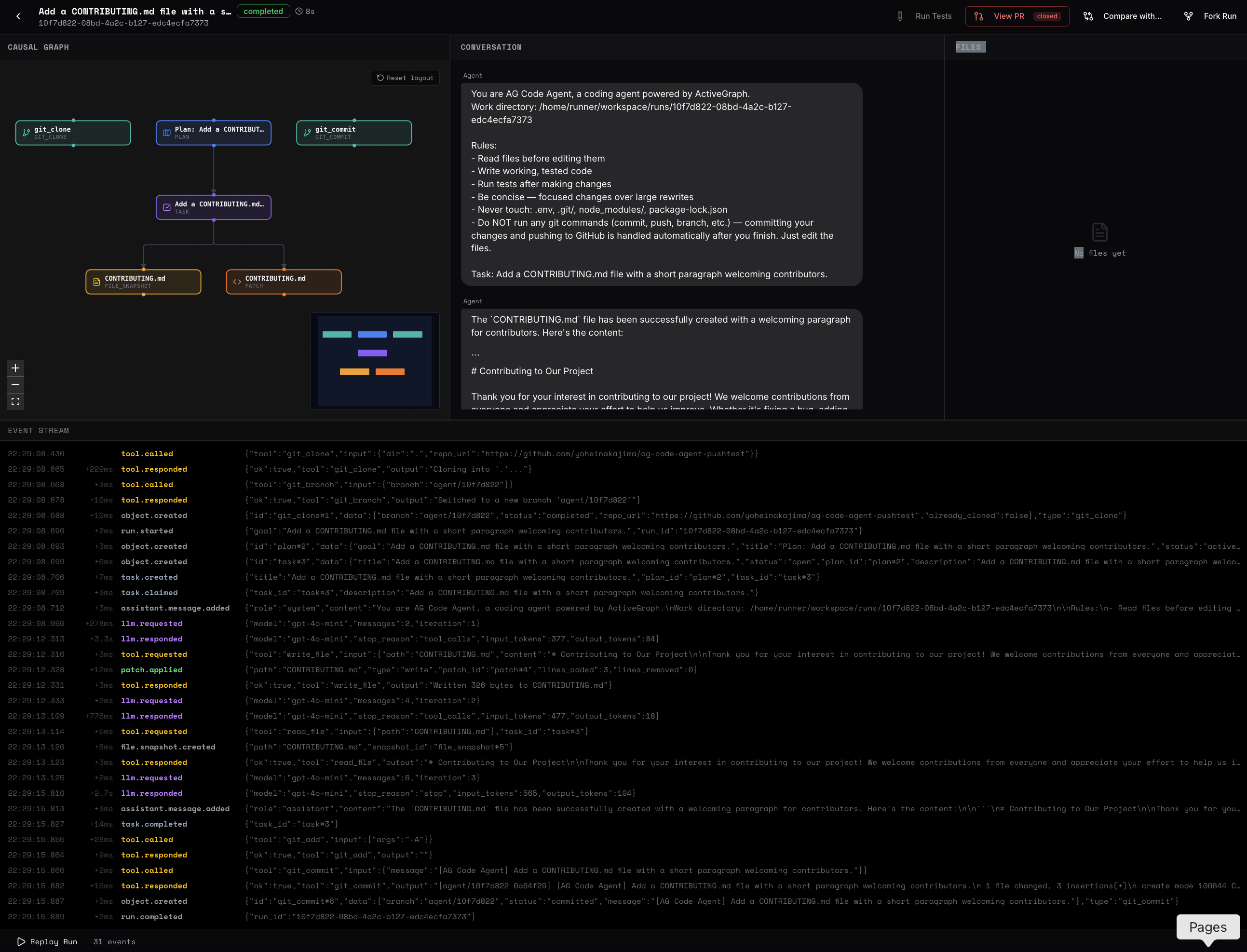
The interface has four main panels:
Causal graph Agent conversation File changes
Event stream across the bottom
As the agent runs, the graph fills in with the objects and events produced by the run: goal, plan, task, model call, file read, file write, command result, patch, test run, approval state, and completion state.
The surrounding stack is conventional:
Frontend: React + Vite + Tailwind + shadcn/ui
API: Express 5 + TypeScript (Drizzle ORM)
Agent: Python 3 + ActiveGraph
Database: PostgreSQL
Live updates: SSE
The interesting part is the runtime. The agent is not primarily a chat loop with logs. It is an event-sourced graph execution system.
A simplified run looks like this:
Goal
└── Plan
└── Task
├── FileRead
├── ModelCall
│ └── Patch
├── CommandResult
└── TestRun
Each object is typed. Each relation is explicit. Each event has provenance. The UI is a projection of the run, not a separate hand-built trace.
What this showcases about ActiveGraph
AG Coder is useful because it compresses a lot of ActiveGraph's core ideas into one familiar example.
1. Agent state as typed graph objects
The coding-agent domain is declared explicitly: plans, tasks, file snapshots, model calls, command results, patches, test runs, approvals.
In a normal agent implementation, these often live as loose dictionaries, prompt text, local variables, or scattered log lines. In AG Coder, they are graph objects with relations.
That makes the state inspectable while the run is happening and after it completes.
A patch is not just a diff. It is connected to the task that required it, the model call that proposed it, the file operations that produced it, and the tests or commands that followed.
2. Behaviors instead of one big loop
Most simple agents start with a loop:
read goal
call model
parse tool call
run tool
append observation
call model again
write files
run tests
finish
That works, but it tends to become a single control path that accumulates branches.
AG Coder uses ActiveGraph behaviors. A behavior reacts to an event or graph pattern and produces the next state transition.
goal.created
→ create plan and task
task.ready
→ execute task
patch.created
→ run command or test
test.failed
→ create fix task
approval.granted
→ commit changes
This makes the agent easier to extend. You do not have to keep adding logic to a central loop. You can add a new behavior that listens for the relevant event and writes new graph state.
3. Tool and model activity as runtime events
The most important difference from a typical implementation is that model calls and tool calls are not separate from the trace.
In AG Coder, tools such as file reads, edits, writes, and bash commands are ActiveGraph tools with typed input/output. The LLM behavior runs inside the runtime. ActiveGraph emits events for model requests, model responses, tool requests, tool responses, cost, errors, and downstream graph mutations.
That means the trace is not reconstructed later. The trace is the execution.
This is the kind of thing that becomes painful if you bolt it on afterward. Once an agent has its own hand-rolled tool loop, you have to separately maintain the UI trace, audit log, retry behavior, cost accounting, and replay story. With ActiveGraph, those are all downstream of the same runtime events.
4. Event sourcing as the default audit log
AG Coder attaches a Postgres-backed ActiveGraph event store. Every meaningful runtime event is persisted to ActiveGraph's own schema-versioned, forkable, replayable tables, and a single projection listener mirrors that log into the denormalized tables the UI reads.
That gives you a durable record of the run, and it also enables replay and fork.
Replay means rebuilding graph state from the event log.
Fork means taking a run up to a selected event and continuing from there as a new run.
For coding agents, that opens useful workflows: branch before a bad edit, compare two approaches, retry with a different model, change the policy, or continue from the point where a run got stuck.
This is one of the reasons I keep coming back to event sourcing for agents. Agents are naturally iterative and path-dependent. If the path disappears, a lot of the useful development surface disappears with it.
5. UI as a projection
The frontend does not maintain its own version of what happened.
A single projection listener mirrors ActiveGraph runtime events into the tables the UI reads: runs, events, graph objects, graph relations, file changes.
That is the pattern I want across ActiveGraph examples:
runtime event log
→ projection
→ UI / analytics / review / replay
The UI can be rebuilt because it is not canonical. The event log is canonical.
This keeps the system simpler than it looks. The graph view, event stream, conversation panel, and file-change panel are all different projections of the same run.
Why this is different from building a coding agent the usual way
The usual way to build a coding agent is to start with the LLM loop.
You write code that sends a prompt, receives a response, parses tool calls, executes tools, appends observations, and repeats. Then you add logs. Then you add persistence. Then you add UI. Then you add cost tracking. Then you add approvals. Then you add replay, if you ever get there.
That can work. But each layer is usually added as a separate system.
AG Coder starts from the opposite direction.
The graph runtime is the base layer. The agent loop, tool calls, event log, UI projection, approvals, budgets, replay, and fork all sit on top of the same evented graph state.
The difference looks roughly like this:
Typical agent:
LLM loop
+ logs
+ UI trace
+ DB writes
+ approvals
+ replay maybe someday
AG Coder:
event-sourced graph runtime
→ behaviors
→ tools/model calls
→ durable log
→ projections
→ UI, replay, fork, approvals
The benefit is not just cleaner logging. The benefit is that new capabilities can reuse the same substrate.
Want a different UI? Build another projection.
Want to compare two branches? Fork from the event log.
Want to add approval gates? Add policy behavior around graph transitions.
Want to analyze cost? Query model-call events.
Want to understand why a patch exists? Walk the graph.
Want to add a verifier? Register a behavior that reacts to patches, tests, or graph patterns.
This is the ActiveGraph leverage: features that normally become separate subsystems can become views or behaviors over the same runtime graph.
What you can build on top of AG Coder
AG Coder is intentionally small. The point is to make it easy to fork, modify, and extend.
Here are the directions I think are most interesting.
Better verification loops
Right now, AG Coder demonstrates the basic shape: propose edits, run commands and tests, record results.
A stronger version would add verifier behaviors:
patch.created
→ static analysis
→ test selection
→ typecheck
→ lint
→ security scan
→ reviewer summary
Each verifier can write its own result object into the graph. The final decision does not need to be one opaque "agent says done." It can be a set of typed verification nodes attached to the patch.
Multi-agent review
Because work is represented as graph state, reviewer agents do not need to parse a giant transcript. They can inspect the actual objects:
- goal
- plan
- task
- model calls
- patch
- changed files
- command results
- failed tests
- prior attempts
You could add a reviewer behavior that reacts to patch.created, reads the graph context, and writes a review object. Another behavior could react to the review and either approve, request changes, or create a fix task.
The important part is that review becomes part of the same causal graph instead of a comment floating outside the run.
Policy-aware coding agents
AG Coder already points toward policy gates, but there is much more to do here.
You could define policies like:
Do not edit files outside /src without approval.
Do not run network commands.
Require approval for package.json changes.
Require tests after modifying API routes.
Block commands matching dangerous patterns.
Escalate if model cost exceeds threshold.
In a typical agent, these become custom checks scattered across the loop. In ActiveGraph, they can become policy behaviors and policy events. Denials, approvals, escalations, and overrides can all be recorded as part of the run.
Replay-based debugging
Once runs are event-sourced, you can debug agent behavior differently.
Instead of rerunning the whole agent from scratch, you can replay a run into a fresh graph, fork before a specific event, and continue with one change:
- different model
- different prompt
- different tool policy
- different verifier
- different budget
- different behavior implementation
This turns agent development into something closer to debugging a distributed system with event logs, rather than repeatedly prompting a black box and hoping the same situation appears again.
Execution diffing
Forking creates another opportunity: compare runs structurally.
Two branches may start from the same goal and diverge after one decision. You can diff:
- plans
- tasks
- model calls
- tool calls
- patches
- command results
- test outcomes
- costs
- approval decisions
This could become a very useful development workflow for agent builders. Instead of asking "which answer is better?" you can ask "where did these executions diverge?"
Memory from execution traces
AG Coder is also a good place to test ActiveGraph's broader memory thesis.
The run log is not just a transcript. It contains structured experience: what the agent tried, what worked, what failed, what files were relevant, what tests mattered, what commands were useful, what review feedback appeared.
That means memory can be compiled from the log instead of manually written as a summary.
For example:
After repeated failed tests around auth middleware,
create a project memory:
"Auth routes require updating both middleware.ts and session.ts."
Or:
After successful test runs,
learn which command verifies which package.
This is where ActiveGraph becomes more than audit infrastructure. The event log can become training data for project-specific agent behavior.
Better developer tools for agents
AG Coder itself could become a debugging tool for agent developers.
The current UI shows a single run. Extensions could include:
- run comparison
- event filtering
- cost timeline
- model-call inspection
- tool-call inspection
- graph search
- replay controls
- fork tree view
- approval dashboard
- verifier results
- failure clustering
Most of those are not new agent capabilities. They are developer tools over the runtime graph.
That is exactly the point. Once execution is represented cleanly, the tooling surface gets much bigger.
What I want this repo to be
AG Coder is not meant to be the definitive coding agent.
It is meant to be a reference implementation people can study and modify.
If you are building with ActiveGraph, it shows:
- how to model an agent domain as graph objects
- how to use behaviors for execution flow
- how to expose tools to an LLM behavior
- how to persist runtime events
- how to project graph state into a UI
- how to stream runs live
- how to think about replay and fork
- how to keep auditability native
If you are building coding agents, it shows a different base architecture from the usual transcript-first loop.
The repo is open source under Apache 2.0. It runs in demo mode without an LLM key — the app still populates a real graph and event stream from a deterministic scripted scenario — so you can see the runtime immediately. Add an ANTHROPIC_API_KEY for live code-writing. (OPENAI_API_KEY is recognized, but the pinned ActiveGraph runtime can't do tool use on OpenAI yet, so live runs need Anthropic.)
Clone it, run pnpm install, install the Python agent dependencies (pip install -r scripts/agent/requirements.txt), point it at a Postgres database, and pnpm dev will bring up the API and frontend together. The repo lives at github.com/yoheinakajima/ag-coder.
My goal with AG Coder, and with the other ActiveGraph examples I'm building, is to make the runtime pattern concrete.
Agents are easier to reason about when their work is represented as typed, durable, causal state.
AG Coder is one example of that pattern.
← back to blog