Evidence Compilation Before Semantic Memory: ActiveGraph on LongMemEval-S
Technical benchmark note: 85.6% QA accuracy and 86.2% turn answer-in-context at 2,462 mean context tokens, with deterministic non-generative ingestion.
- research
- benchmark
Technical benchmark note: 85.6% QA accuracy and 86.2% turn answer-in-context at 2,462 mean context tokens, with deterministic non-generative ingestion.
I have been building ActiveGraph, an event-sourced graph runtime for AI agents: the append-only event log is the source of truth, the working graph is a deterministic projection of that log, and behaviors react to graph state by emitting new events. For the underlying runtime design, see the already-published architecture note, The Log is the Agent.
This post tests a narrow prerequisite for ActiveGraph: whether the runtime substrate can compile useful evidence from long conversational histories before semantic memory is added.
The main scientific comparison is ActiveGraph vs. dense turn-level RAG. In this single paired run, ActiveGraph is statistically tied with that baseline, not proven better: 85.6% vs. 83.6% at a matched ~2.4k-token context budget, with McNemar p = 0.132. The same run is also statistically tied with the gold-session oracle used by the harness, while significantly outperforming session-level retrieval, lexical retrieval, BM25 retrieval, and full-history prompting diagnostics.
The retrieval-side result is now measured and statistically tested. Excluding the 30 abstention questions, an answer-in-context sidecar shows that ActiveGraph places labeled gold evidence turns in context on 86.2% of questions, versus 81.7% for dense turn-RAG - 21 fewer turn-level misses across 470 non-abstention questions. The turn-AIC gap is statistically established by exact McNemar over the 470 per-question hit/miss vectors: 25 questions where only ActiveGraph retrieved the gold turn vs. 4 the other way, p = 0.0001. ActiveGraph also has more reader-failed-with-evidence cases, 35 vs. 27, so the story is not "uniformly better." The nominal QA edge is accompanied by a statistically established retrieval-side edge, despite a slightly higher reader-failed-with-evidence rate.
The result says something narrower and more useful than "graph memory beats RAG":
The event-sourced substrate does not appear to be a retrieval tax. It already supports compact deterministic evidence compilation before semantic memory is added.
It does not establish graph topology as the causal mechanism. It does not claim that ActiveGraph is a finished memory system. It establishes a substrate checkpoint: retrieval can live inside the ActiveGraph runtime without paying an obvious LongMemEval-S performance penalty.
The exact claim
Here is the claim hierarchy for this post:
| Claim | Status in this post |
|---|---|
| ActiveGraph reaches 85.6% on cleaned LongMemEval-S at 2,462 mean context tokens. | Supported by the run. |
| ActiveGraph is statistically tied with dense turn-RAG in this run. | Supported; this is the primary comparison. Nominal +2.0 points, McNemar p = 0.132. |
| ActiveGraph retrieves labeled gold evidence more often than dense turn-RAG. | Measured by the answer-in-context sidecar: 86.2% vs. 81.7% turn-AIC; 94.9% vs. 93.0% session-AIC, n = 470. Paired significance is established by exact McNemar: 25 vs. 4 discordant turn-AIC hits, p = 0.0001. Still not graph-causal proof. |
| ActiveGraph is statistically tied with the gold-session oracle in this harness. | Supported as a single-run paired result; not a formal equivalence claim and not a perfect-retrieval ceiling. |
| ActiveGraph significantly beats session-RAG, lexical ActiveGraph, BM25, and full-history diagnostics. | Supported; useful sanity checks, not the main scientific comparison. |
| ActiveGraph's graph topology caused the result. | Not established. Needs ablations. |
| ActiveGraph is a finished semantic-memory system. | Not claimed. |
Claim hierarchy for this post.
LongMemEval-S is useful here precisely because it is narrow. It mostly tests evidence recovery from long conversations: can a system retrieve, compress, order, and present the right pieces of history under a constrained context budget? It does not test replayability, fork/diff, provenance, behavior governance, or rich update semantics. So this result should be read as a substrate check, not as a final memory-system result.
The important conclusion is not that semantic memory is proven. It is that the event-sourced substrate can host a deterministic evidence-compilation pipeline without obvious degradation. Semantic writes, update semantics, provenance-aware memory evolution, and agent-experience memory remain follow-up hypotheses for me or anyone else who wants to build on this harness.
What was tested
This run tests the deterministic retrieval substrate:
- conversations are ingested as events;
- sessions and turns become addressable runtime objects;
- basic temporal and co-occurrence structure is available for context assembly;
- turns are scored with embeddings or lexical overlap;
- a compact context is assembled deterministically under a token budget;
- an LLM reader answers from that retrieved context.
There is no LLM-generated memory at ingest: no summarization, no fact extraction, no entity extraction, no reflection agent, no learned graph construction, and no LLM-mediated compression. An LLM is used as the reader after retrieval, and GPT-4o is used as the judge.
That distinction matters because many higher public LongMemEval scores rely on LLM-generated observations, summaries, extracted memories, reflection, reranking, stronger readers, or larger context windows. Those are valid systems choices. The narrower question here is how far deterministic ingestion and evidence compilation get before generative memory writing is added.
Benchmark and setup
LongMemEval is a benchmark for long-term chat memory. The model receives a long multi-session conversation history and a question whose answer is buried somewhere in that history. The benchmark targets long-term memory abilities including information extraction, multi-session reasoning, knowledge updates, temporal reasoning, and abstention.
For this run I used the cleaned s split:
| Field | Value |
|---|---|
| Dataset | longmemeval_s_cleaned.json |
| SHA-256 | d6f21ea9d60a0d56f34a05b609c79c88a451d2ae03597821ea3d5a9678c3a442 |
| Questions | 500 |
| Reader | Claude Sonnet resolved as claude-sonnet-4-5-20250929 , temperature 0, max tokens 1024, no tools, no web |
| Judge | gpt-4o-2024-08-06 , temperature 0 |
| Run type | single full run, one seed |
Run identity and provenance.
All systems share the same prompt template and reader settings. Accuracy differences should therefore be read as differences in retrieved and assembled context, not differences in downstream model choice.
LongMemEval-S is not the final target for ActiveGraph. Newer agent-memory work, including LongMemEval-V2, moves closer to environment experience: interface affordances, state dynamics, workflows, recurring failure modes, and premise awareness. That is closer to what ActiveGraph is meant to preserve. LongMemEval-S is a conversational recall checkpoint before testing the runtime on richer agent-experience memory.
Main result
The main comparison is ActiveGraph vs. dense turn-level RAG at roughly the same context budget: around 2.4k retrieved-context tokens. The gold-session oracle, session-level RAG, lexical retrieval, and full-history prompting are included as diagnostics.
By token budget, I mean the amount of retrieved or assembled evidence handed to the reader model, not the size of the original conversation history. LongMemEval-S histories are roughly 115k tokens, but a memory system's job is to compile a much smaller evidence bundle. Budget matters because it affects cost, latency, prompt-cacheability, and reader behavior. More context can help when it adds evidence, but it can also bury the answer in distractors. A LongMemEval score without a context budget is incomplete: 85% at 2.5k tokens and 85% at 30k tokens are different systems.
| System | Granularity | Accuracy | Correct / 500 | Wilson 95% CI | Mean context tokens | Role |
|---|---|---|---|---|---|---|
| gold-session oracle ( full-context-oracle ) | - | 0.868 | 434 | [0.836, 0.895] | 5,650 | diagnostic upper bound |
| activegraph-det-embedding | - | 0.856 | 428 | [0.823, 0.884] | 2,462 | main |
| rag-dense | turn | 0.836 | 418 | [0.801, 0.866] | 2,366 | main |
| rag-bm25 | turn | 0.730 | 365 | [0.689, 0.767] | 2,516 | diagnostic |
| activegraph-det-lexical | - | 0.618 | 309 | [0.575, 0.660] | 2,436 | ablation |
| rag-bm25 | session | 0.560 | 280 | [0.516, 0.603] | 27,376 | diagnostic |
| rag-dense | session | 0.548 | 274 | [0.504, 0.591] | 24,133 | diagnostic |
| full-context-s | - | 0.192 | 96 | [0.160, 0.229] | 103,743 | diagnostic |
End-to-end QA accuracy by system on cleaned LongMemEval-S (n=500).
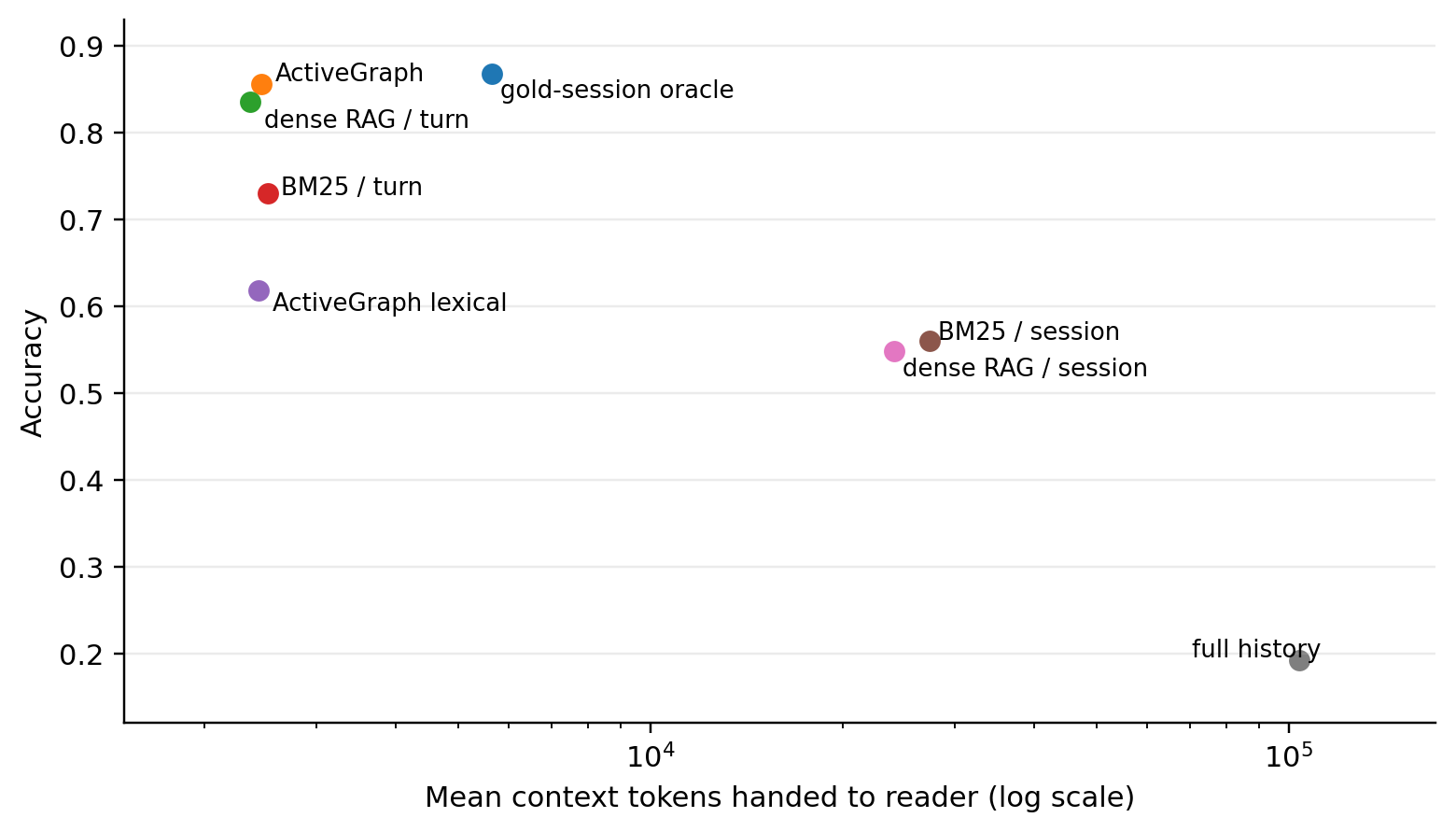
Figure 1. ActiveGraph is within noise of the gold-session oracle (-1.2 points, n.s.) at a small context budget. Session-level retrieval uses roughly 10x more context and scores much lower. Full-history prompting uses roughly 42x more context than ActiveGraph and collapses in this reader/prompt/judge setup.
The short read:
- The comparison to care about most is ActiveGraph vs. dense turn-RAG. ActiveGraph is +2.0 points, but that edge is not statistically established.
- A retrieval-only answer-in-context sidecar now shows that the nominal edge is accompanied by a statistically established retrieval edge: ActiveGraph retrieves labeled gold turns more often, 86.2% vs. 81.7% on the 470 non-abstention questions, with exact McNemar p = 0.0001.
- ActiveGraph is -1.2 points below the gold-session oracle, and that gap is not statistically significant in this run.
- The large wins over session-level retrieval, BM25, lexical ActiveGraph, and full-history prompting are sanity checks that compact evidence assembly matters. They are not the claim that ActiveGraph beats the strongest retrieval systems.
The full-context result should be read narrowly: with this reader, prompt, and judge, dumping the entire history into the prompt performed very poorly. That row should not be generalized to every long-context model, prompt, or reasoning strategy. The broader lesson is more modest: larger context is not automatically better memory.
What is significant and what is not
Because every system is evaluated on the same 500 questions, the right test is paired. I used McNemar on per-question correctness. In the table below, b10 means ActiveGraph correct and the comparison system wrong; b01 means the comparison system correct and ActiveGraph wrong. I also report paired bootstrap confidence intervals for the accuracy difference.
I put the two key comparisons first: dense turn-RAG and the gold-session oracle. The remaining rows are diagnostics.
| ActiveGraph-embedding vs. | Net | b10 / b01 | McNemar p | Delta acc [95% CI] |
|---|---|---|---|---|
| rag-dense / turn | +10 | 23 / 13 | 0.132 | +0.020 [-0.002, +0.044] |
| gold-session oracle ( full-context-oracle ) | -6 | 24 / 30 | 0.497 | -0.012 [-0.040, +0.018] |
| rag-bm25 / turn | +63 | 76 / 13 | <0.001 | +0.126 [+0.092, +0.162] |
| activegraph-det-lexical | +119 | 132 / 13 | <0.001 | +0.238 [+0.196, +0.280] |
| rag-dense / session | +154 | 169 / 15 | <0.001 | +0.308 [+0.264, +0.354] |
| rag-bm25 / session | +148 | 163 / 15 | <0.001 | +0.296 [+0.250, +0.342] |
| full-context-s | +332 | 337 / 5 | <0.001 | +0.664 [+0.620, +0.706] |
Paired McNemar comparisons against ActiveGraph-det-embedding.
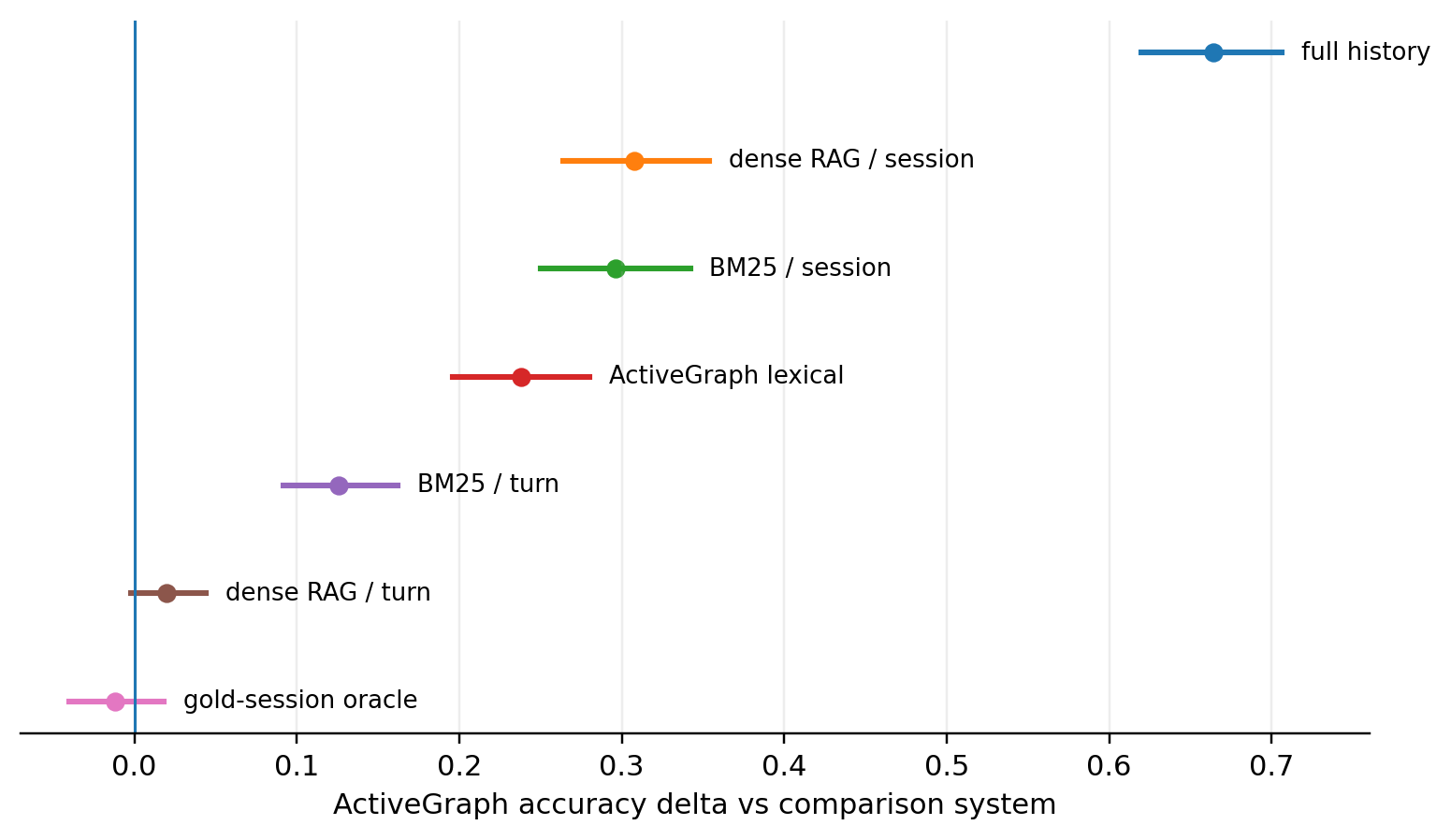
Figure 2. The dense turn-RAG and gold-session oracle comparisons cross zero, so the statistically correct wording is "tied in this run," not "beats." The large gaps against the diagnostic baselines are far from zero.
The main comparison is a tie. Against dense turn-RAG, the +2 point nominal edge comes from only 36 discordant questions: 23 ActiveGraph wins and 13 dense-RAG wins. McNemar p = 0.132 and the paired bootstrap interval grazes zero. This is not enough to claim superiority over dense turn-RAG.
The diagnostic gaps are real within this run. Session-level retrieval, lexical ActiveGraph, BM25 turn retrieval, and full-history prompting are far below ActiveGraph here. Those rows are useful because they show that context granularity, scoring signal, and evidence assembly matter. They should not be confused with the strongest local comparison.
The gold-session oracle comparison is interesting but limited. ActiveGraph is not significantly worse than the gold-session oracle in this single paired run, despite having to find useful evidence itself and using less than half the oracle's context. But failure to reject a difference is not proof of equality; a formal equivalence or non-inferiority claim would require a margin declared in advance. Also, this is not a perfect-retrieval ceiling. The gold-session oracle receives the answer sessions, but those sessions can still contain distractor turns, and the result still depends on this reader, prompt, and judge stack. So "near the gold-session oracle" means near this benchmark oracle in this setup, not solved retrieval in general.
Retrieval-side result: answer-in-context
End-to-end QA accuracy still mixes two things: whether retrieval surfaced the evidence, and whether the reader used it correctly. I added a retrieval-faithful sidecar to separate those pieces for the two main systems: ActiveGraph-det-embedding and dense turn-RAG.
The sidecar replays retrieval only over the already-completed cells from the same 20260524T050742Z matrix. It makes no reader call and no LLM call beyond query embedding. It also asserts that the reconstructed context is byte-identical to the context fed to the reader in the published run. The scorer then checks the assembled context against LongMemEval's gold evidence labels. The 30 abstention questions have no gold evidence location and are excluded, matching the upstream retrieval-metric convention, leaving n = 470.
Definitions:
- turn-AIC: the fraction of questions where all labeled gold evidence turn IDs are included in the retrieved context.
- session-AIC: the same check at session level.
- rfwe: reader-failed-with-evidence - questions judged wrong even though labeled evidence was retrieved.
| System | turn-AIC | session-AIC | QA acc on n=470 | turn misses | session misses | rfwe |
|---|---|---|---|---|---|---|
| activegraph-det-embedding | 0.862 | 0.949 | 0.849 | 65 | 24 | 35 |
| rag-dense / turn | 0.817 | 0.930 | 0.830 | 86 | 33 | 27 |
Retrieval-faithful answer-in-context sidecar (n=470).
This changes the interpretation in a useful way. The +2 point QA edge over dense turn-RAG is still not statistically established as an accuracy win, but it is accompanied by a statistically established retrieval-outcome edge: ActiveGraph places the labeled gold evidence turn in context on 4.5 more points of questions - 21 fewer turn-level misses across 470. I quantify that gap with the same paired test used for QA: an exact McNemar over the sidecar's per-question turn-AIC hit/miss vectors. The discordance is strongly one-directional - 25 questions where ActiveGraph alone placed the gold turn in context versus 4 where only dense turn-RAG did (p = 0.0001) - so the +4.5-point turn-AIC edge is statistically established as a retrieval-outcome win, though still not graph-causal proof. For ActiveGraph, retrieval and end-to-end accuracy nearly coincide in this cell: 86.2% turn-AIC and 84.9% QA accuracy. That means the reader usually succeeds when labeled evidence is present, with important exceptions described below: multi-session and temporal still have turn-level retrieval headroom, while knowledge-update is more of a reader-reconciliation problem.
The counter-pressure matters too: ActiveGraph has slightly more reader-failed-with-evidence cases, 35 vs. 27. The retrieval win and the reconciliation cost are the same order of magnitude: +21 net turn-AIC hits (25 won, 4 lost) against +8 reader-failed-with-evidence cases (35 vs. 27). The significant retrieval advantage is partly absorbed by reader-failed-with-evidence cases on the additional context ActiveGraph surfaces, which helps account for why end-to-end QA lands at a non-significant +2.0 rather than tracking the full retrieval gap. The AIC edge and the QA tie are compatible, not contradictory.
One plausible mechanism is context assembly: ActiveGraph sometimes retrieves more labeled evidence while also surrounding it with adjacent or competing context. That can help when dense RAG misses the exact turn, but it can also make superseded-fact reconciliation harder for the reader. The AIC metric cannot prove this; per-example RFWE audits would be the right check.
One caveat applies to all systems: this metric measures whether labeled gold evidence reached the reader, not whether sufficient evidence did. If a question is answerable from unlabeled context, the metric can count a spurious reader-failed-with-evidence case. That is the standard limitation of has_answer-based evidence metrics, and it applies equally to both systems.
How it works, briefly
For this benchmark, ActiveGraph is used as an event-sourced memory index. The retrieval and assembly path is:
- Ingest sessions and turns as events.
- Replay the event log into addressable session and turn objects.
- Build basic temporal and co-occurrence structure over those objects.
- Score turns against the question with embedding similarity, or lexical overlap for the ablation.
- Select seed turns.
- Expand deterministically around seeds using temporal/co-occurrence structure.
- Deduplicate and pack selected evidence under the token budget.
- Render the final evidence bundle in chronological order to the reader.
The activegraph-det-lexical row uses the same machinery with keyword-style scoring instead of embedding scoring. It reaches 61.8%, which says the embedding signal is doing much of the work.
The important caveat is not a footnote: ActiveGraph-embedding differs from dense turn-RAG as a bundle. It differs in scoring, temporal expansion, context packing, and graph/object representation. This run cannot attribute the result to graph topology specifically. It validates the pipeline as a bundle.
The defensible claim is:
ActiveGraph's deterministic evidence-compilation pipeline is competitive with dense turn-RAG and significantly better than weaker local diagnostics.
The not-yet-defensible claim is:
Graph topology is the isolated causal reason.
To make that causal claim, a future ablation would need to remove temporal links, co-occurrence links, neighbor expansion, and packing choices one at a time, while holding the scoring model fixed.
Per-type breakdown
Against dense turn-level RAG, the QA per-type pattern is useful but not dispositive. I report raw counts because several deltas are small.
| Question type | ActiveGraph QA | dense RAG / turn QA | Net |
|---|---|---|---|
| single-session-user | 67 / 70 | 66 / 70 | +1 |
| single-session-assistant | 56 / 56 | 56 / 56 | 0 |
| single-session-preference | 25 / 30 | 23 / 30 | +2 |
| multi-session | 103 / 133 | 96 / 133 | +7 |
| temporal-reasoning | 106 / 133 | 102 / 133 | +4 |
| knowledge-update | 71 / 78 | 75 / 78 | -4 |
Per-question-type net counts: ActiveGraph vs. dense turn-RAG.
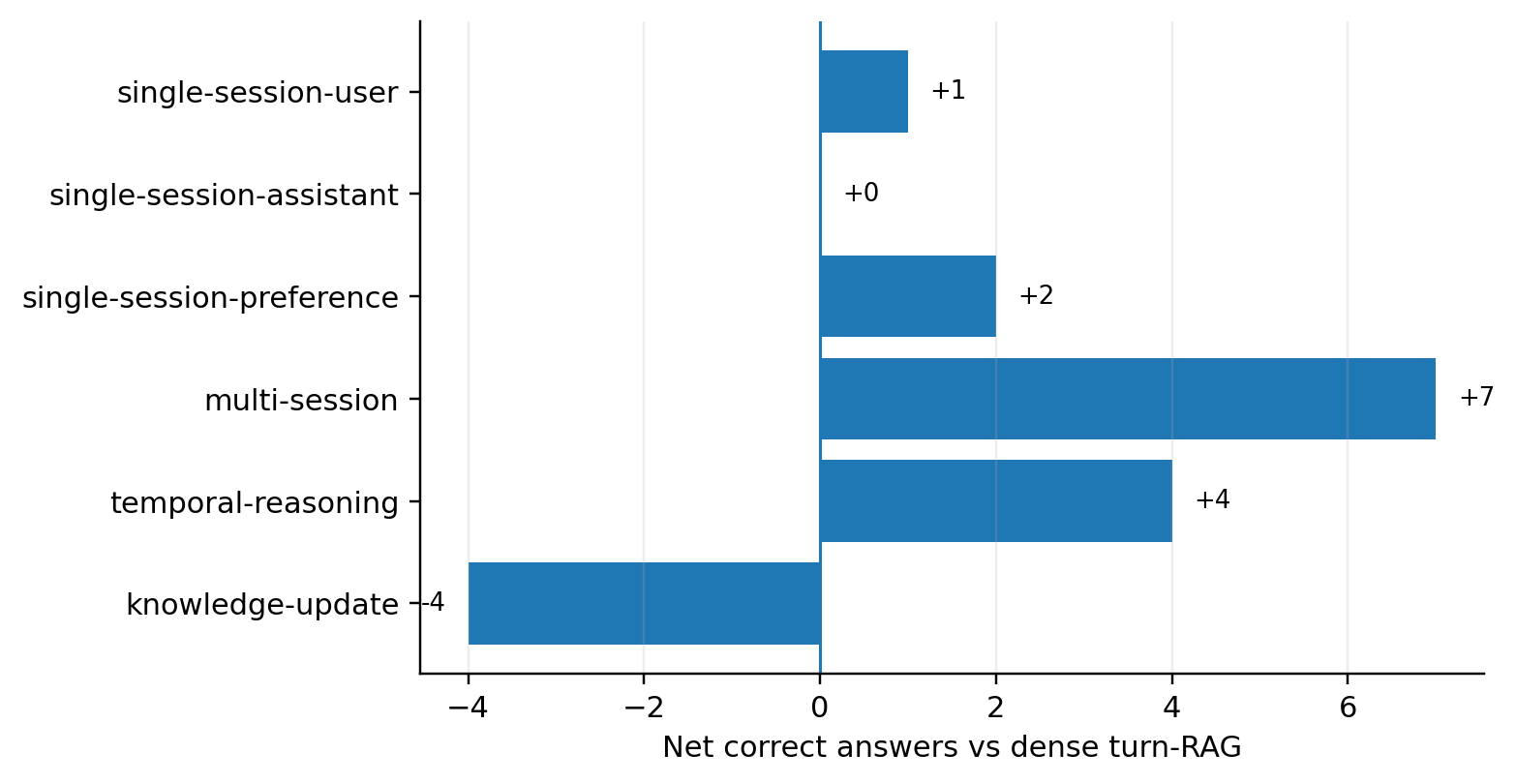
Figure 3. The nominal ActiveGraph advantage over dense turn-RAG comes mostly from multi-session and temporal-reasoning questions. The category where it loses is knowledge-update.
The answer-in-context sidecar makes that pattern more informative. In the table below, n excludes abstention questions.
| Question type | n | AG turn / session AIC | AG QA | dense turn / session AIC | dense QA | Net turn-AIC |
|---|---|---|---|---|---|---|
| knowledge-update | 72 | 95.8% / 98.6% | 90.3% | 94.4% / 100.0% | 95.8% | +1.4 |
| multi-session | 121 | 76.0% / 95.9% | 75.2% | 67.8% / 92.6% | 70.3% | +8.2 |
| temporal-reasoning | 127 | 79.5% / 85.8% | 79.5% | 72.4% / 81.1% | 76.4% | +7.1 |
| single-session-user | 64 | 98.4% / 100.0% | 95.3% | 98.4% / 100.0% | 93.8% | 0.0 |
| single-session-assistant | 56 | 100.0% / 100.0% | 100.0% | 100.0% / 100.0% | 100.0% | 0.0 |
| single-session-preference | 30 | 80.0% / 100.0% | 83.3% | 76.7% / 100.0% | 76.7% | +3.3 |
Per-question-type answer-in-context and accuracy.
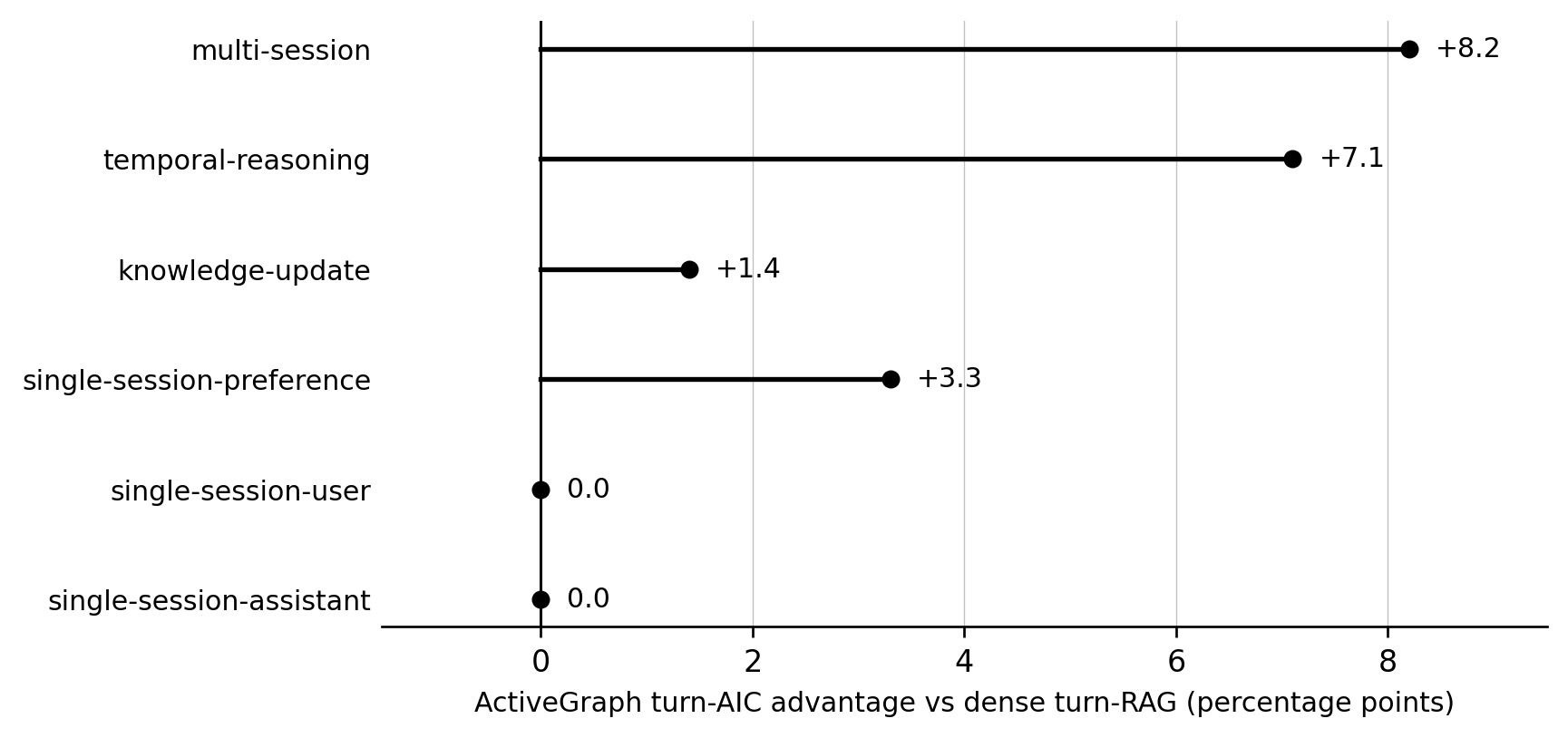
Figure 4. ActiveGraph's turn-level answer-in-context advantage over dense turn-RAG is concentrated in multi-session and temporal-reasoning questions. This is a retrieval-outcome measurement, not an ablation proving graph causality.
The knowledge-update result reverses my earlier interpretation. I originally expected the semantic layer to help because the system might be failing to retrieve superseded facts from prose. The AIC data says that is not the main problem here. Both systems retrieve knowledge-update evidence at roughly ceiling: ActiveGraph 95.8% turn-AIC and 98.6% session-AIC; dense turn-RAG 94.4% turn-AIC and 100.0% session-AIC. ActiveGraph even retrieves the labeled knowledge-update evidence marginally more often, yet scores lower, 90.3% vs. 95.8%, because it has more reader-failed-with-evidence cases: 5 vs. 2 out of 72.
So the knowledge-update hypothesis should be narrower: a future semantic layer should help by marking facts as superseded before assembly, easing reader reconciliation, not by improving retrieval recall. Retrieval recall is already near ceiling there - roughly 95% turn-AIC and about 99% session-AIC for both systems - so this benchmark structurally cannot tell whether typed superseded-fact representation helps. The bottleneck it would address is not retrieval; it is reader reconciliation.
The multi-session and temporal categories tell a different story. Both systems often find the right session but miss the exact labeled turn. For multi-session, ActiveGraph has 95.9% session-AIC but only 76.0% turn-AIC; dense turn-RAG has 92.6% session-AIC but only 67.8% turn-AIC. Accuracy tracks turn-AIC more than session-AIC. These are the categories with real turn-level retrieval headroom, and they are also the categories where ActiveGraph's retrieval advantage is largest.
That signature is directionally consistent with the RAG-vs-GraphRAG literature: structured retrieval tends to matter most on multi-hop and reasoning-intensive questions. But it is still not proof that ActiveGraph's graph topology is the causal mechanism. The same confound remains: scoring, expansion, packing, ordering, and graph/object representation move together in this run.
The evidence-compilation landscape
I do not think the right comparison is "memory systems" in general. The narrower comparison is evidence compilation for long conversational histories: how a system indexes, searches, ranks, truncates, orders, renders, and hands evidence to the reader.
This avoids two traps. First, retrieval recall numbers are not the same thing as end-to-end QA accuracy. Second, public LongMemEval reports use different readers, judges, budgets, versions, top-k settings, and ingestion pipelines. They are useful landmarks, not one clean leaderboard.
ActiveGraph is not the highest public LongMemEval number. The point of the table is positioning: ingest path, token budget, and comparability. Scores give scale; they are not apples-to-apples rankings.
Nearby deterministic or low-write-time systems
| Lane / system | Ingest or write path | Reported budget | Reported result | Why it matters here |
|---|---|---|---|---|
| ActiveGraph current run | No generative memory writing; deterministic event ingestion + cached embeddings | 2,462 mean tokens | 85.6% end-to-end QA | The substrate result: compact evidence compilation without LLM-written memory. |
| Local dense turn-RAG | No generative memory writing; dense turn retrieval | 2,366 mean tokens | 83.6% end-to-end QA | The main scientific comparison in this post; ActiveGraph is tied, not superior. |
| SmartSearch | No LLM in retrieval loop; learned rerankers used | ~3.1k-3.4k tokens | 88.4% end-to-end QA | Strong nearby evidence that ranking, expansion, and truncation matter. |
| True Memory Pro | No extraction-at-ingest; raw events preserved | Not reported here as comparable context budget | 87.8% LongMemEval, 3-run mean | Relevant comparator for preserved-event memory without write-time extraction. |
| Memanto | No LLM-mediated ingestion claimed | Not reported here as comparable context budget | 89.8% on LongMemEval | Strong nearby example for high score without LLM-heavy ingestion. |
Comparison lanes: ingest path, budget, and reported result.
Broader context and non-apples-to-apples systems
The broader public landscape is useful context, but it is not a leaderboard for this post.
- Mastra OM reports 84.23% with GPT-4o and 94.87% with GPT-5-mini, using Observer/Reflector agents that write observations and reflections and an average context window around 30k tokens. That is a valid architecture, but it is a generative write-time memory system with a different reader setup and much larger context.
- Mem0 is the strongest challenge to a simple "low budget" story: it reports 94.4% on LongMemEval at 6,787 mean tokens. If the only goal is reported accuracy per token on a public LongMemEval-style setup, that matters. The distinction here is deterministic, non-generative ingestion and a replayable event substrate, not a claim that higher-scoring extraction-based systems do not count.
- Hindsight reports 83.6% with an OSS-20B backbone and 91.4% with larger backbones. It is philosophically close because it uses structured facts and reflection, but it tests a richer memory-writing architecture.
- Backboard / full-history-style reports are useful context for the landscape, but they are not compact evidence-compilation comparisons.
LongMemEval-V2 is not in the table because it is a different benchmark rather than a memory system. I include it in the references because its agent-trajectory framing is a more natural future target for ActiveGraph as a runtime substrate.
The better positioning is:
ActiveGraph is not the highest public LongMemEval number. Its narrower position is that it is a low-context, non-generative-ingestion substrate result: 85.6% end-to-end QA at 2.4k context tokens, with paired statistics, pinned artifacts, and a replayable event-sourced runtime underneath. The token budget and ingest path are both part of the claim.
How this aligns with RAG, GraphRAG, and harness work
Recent RAG vs. GraphRAG work argues that there is no universal winner: graph-based systems often help on multi-hop and reasoning-intensive tasks, while standard retrieval can remain strong on direct factual lookup. The directional pattern here is consistent with that trade-off, but it does not prove ActiveGraph's graph topology caused the result.
Another line of work is just as relevant: harness and ranking can matter as much as the retriever. SmartSearch argues that ranking and truncation can dominate memory benchmark performance. "Is Grep All You Need?" shows that retrieval results change substantially across agent harnesses and tool-delivery styles. This supports the more careful unit of analysis:
The unit of comparison is not vector vs. lexical vs. graph. The unit of comparison is the full evidence-compilation pipeline: indexing, query formation, ranking, expansion, truncation, ordering, context rendering, and reader behavior.
A skeptical reading is fair: this result validates deterministic evidence compilation more than graph memory. The graph is the substrate the retrieval lives inside; it is not yet proven to be the reason for the score. The ActiveGraph-specific bet is that putting retrieval inside a replayable event-sourced runtime makes the next layer - semantic writes, provenance, forks, diffs, and behavior changes - governable in a way stateless retrieval pipelines cannot provide.
Lineage: from MindGraph to ActiveGraph
This benchmark sits in a longer line of graph-memory experiments. In 2024 I open-sourced MindGraph, a proof-of-concept starter kit for building and querying an expanding knowledge graph through natural language. MindGraph explored the direct knowledge-graph path: turn natural-language input into nodes and relationships, deduplicate against the existing graph, then query that graph later.
ActiveGraph is a different answer to the same problem. MindGraph treated the graph primarily as a memory layer. ActiveGraph moves graph structure down into the runtime substrate: sessions, turns, events, behaviors, provenance, and memory projections are addressable objects derived from an append-only log.
This benchmark does not use the MindGraph-style extraction path. There are no LLM-generated summaries, facts, entities, dates, or relationships at ingest. The finding is narrower:
The retrieval substrate works before the semantic graph layer is added.
Code surface and benchmark complexity
One practical question is whether ActiveGraph makes this kind of memory easier to build, not only whether it scores well. The honest answer is mixed.
For a one-off LongMemEval retrieval benchmark, no: a plain dense RAG baseline is less code. The benchmark-local ActiveGraph retrieval path is materially larger than the dense baselines because it includes graph projection, retrieval, expansion, packing, and the adapter.
| Surface in this repo | Lines / LOC | Interpretation |
|---|---|---|
| Dense RAG baseline ( rag_dense.py ) | 110 / 90 | Smallest strong local baseline. |
| BM25 baseline ( rag_bm25.py ) | 84 / 65 | Small keyword baseline. |
| ActiveGraph adapter only ( activegraph_det.py ) | 130 / 107 | Thin benchmark interface on top of graph build/retrieve. |
| ActiveGraph local retrieval path ( graph.py + retrieve.py + activegraph_det.py ) | 767 / 638 | Full benchmark-local graph projection, scoring, expansion, packing, and adapter. |
Lines-of-code surface area in this repo.
So this post should not claim that ActiveGraph is currently the shortest way to get a LongMemEval score. A careful dense retriever is simpler for this narrow task.
I did not add LOC for public high-scoring systems because a raw external LOC table would not be honest enough yet. Many are full frameworks, hosted services, workshops, or separate benchmark repos. Counting an entire repository would mostly measure packaging, SDKs, docs, tests, dashboards, integrations, and evaluation harnesses; counting only the memory core would require a documented inclusion rule.
| LOC comparison | Usefulness | Why |
|---|---|---|
| Local baselines in this repo | High | Same harness, same task, same measurement boundary. |
| ActiveGraph local path in this repo | High, but conservative | Includes general substrate code the baselines do not attempt to provide. |
| External memory frameworks | Low without a protocol | Raw repo size mixes memory logic with SDKs, docs, tests, examples, services, and integrations. |
| External benchmark snippets | Low without a protocol | Often measure the eval wrapper, not the production memory system. |
How to interpret LOC across lanes.
That does not mean code surface is irrelevant. It probably matters. But the fair measurement is not raw repository LOC. It is implementation surface under the same requirements: evidence provenance, replay, fork/diff, update semantics, semantic extraction, and controlled memory writes.
So I treat LOC as another reason to keep the claim narrow: this benchmark validates retrieval competence in the substrate, not developer-productivity superiority.
What this says for ActiveGraph
This result matters because ActiveGraph's larger bet is not only retrieval accuracy. It is that long-running agents need experience to accumulate as inspectable state, not as hidden prompt residue or unversioned memory writes.
LongMemEval-S tests one prerequisite: whether the substrate can find and compile relevant evidence from a long event history without relying on a generative memory writer. In this run, the answer appears to be yes; the answer-in-context sidecar makes that retrieval-side claim more concrete.
That support is limited. It says the substrate is not obviously a tax on recall, and that its nominal accuracy edge over dense turn-RAG is accompanied by a statistically established turn-level retrieval edge. It does not prove the semantic-memory layer, update semantics, buildability, controlled runtime changes, or graph-topology causality.
The concrete reason replayability matters is that a future semantic extraction pass could be replayed from the same immutable event history, audited, reverted, forked, or rerun under a different extraction policy. This benchmark does not test that capability; it only establishes that the retrieval substrate is credible enough to be a baseline for that test.
Why you should still be skeptical
I built the system being benchmarked. That is the biggest reason to read this critically.
Mitigations: standard local baselines, matched token budgets for the main comparison, tool-free reader, frozen external judge, hash-pinned data, public harness, per-cell manifests, paired significance tests, and transparent reporting of the non-significant dense-RAG comparison.
Still missing:
- Retrieval metrics beyond the sidecar. Answer-in-context is now reported for ActiveGraph and dense turn-RAG: 86.2% / 94.9% turn/session AIC for ActiveGraph, 81.7% / 93.0% for dense turn-RAG, with exact McNemar p = 0.0001 over paired turn-AIC hit/miss vectors. Still missing: evidence recall@k curves, per-example reader-failed-with-evidence audits, session-AIC and per-type significance checks, and the same retrieval-side breakdown for more baselines.
- Multiple seeds. The paired tests quantify within-run uncertainty, not run-to-run variance.
- Graph ablations. Drop temporal edges, co-occurrence edges, neighbor expansion, and context-packing choices one at a time.
- Stronger RAG baselines. Dense retrieval plus reranking, query expansion, temporal filtering, stronger embedding models, and better context packing.
- Judge robustness. Rejudging the dense-RAG discordant set with a second judge would test whether the nominal +2 point edge is judge-sensitive.
- Cost and latency. Ingest time, retrieval time, embedding calls, storage size, graph size, and reader tokens.
- Code-surface audit. A fair buildability comparison would compare implementation surface under the same requirements rather than raw repository LOC.
- External reproduction. The harness is open, but the result is still self-reported until someone else reruns it.
None of those are claims in this post. They are obvious follow-up measurements that could move the result from a careful benchmark note toward a stronger systems paper.
One methodological story is worth keeping. On a 50-question smoke run, ActiveGraph's temporal-reasoning looked bad, around 0.57. I started building fixes. The full 500-question run put temporal-reasoning at 0.797, ahead of dense turn-RAG. The "weakness" was sampling noise: the temporal slice of a 50-question run is tiny, and a few flipped examples change the story. Small evals catch crashes; they do not measure accuracy.
The other lesson: my first version accidentally benchmarked a from-scratch graph implementation that was not actually using the ActiveGraph package. Same folder name, real numbers, wrong system. A one-line grep for the package API caught it before publishing. Step one of benchmarking your own work is confirming the system under test is the system you think it is.
Reproducing the result
The benchmark harness is in yoheinakajima/activegraph-longmemeval. The repo pins the LongMemEval submodule, Python version, reader settings, judge model, embedding model, lockfile, dataset checksums, per-run manifests, and token counts.
I cut three relevant releases. The original QA benchmark snapshot remains v0.1-paper-longmemeval-s, at commit 3fb54a4, with the stats appendix script and the run-matrix pipe fix included. The answer-in-context sidecar and retrieval results ship in v0.2-paper-longmemeval-s, at commit 094dcae, with scripts/aic_sidecar.py, scripts/answer_in_context.py, and paper/aic_results.md. The paired AIC significance check ships in v0.2.1-paper-longmemeval-s, at commit a3913a9, with scripts/aic_mcnemar.py. The original QA run and 20260524T050742Z matrix are unchanged; v0.2 and v0.2.1 add retrieval-side measurement and post-processing on top of them.
From the repo root, the launch path should be:
make setup
make data
make reproduce-full
python scripts/stats_appendix.py \
--matrix runs/matrix_20260524T050742Z.json \
--dataset s \
--focus activegraph-det-embedding
For the v0.2/v0.2.1 answer-in-context numbers, run the sidecar and scorer once per completed cell directory, then run the paired McNemar script. For example:
AG_RUN_DIR=<completed activegraph-det-embedding run dir>
DENSE_RUN_DIR=<completed rag-dense turn run dir>
python scripts/aic_sidecar.py "$AG_RUN_DIR"
python scripts/answer_in_context.py "$AG_RUN_DIR"
python scripts/aic_sidecar.py "$DENSE_RUN_DIR"
python scripts/answer_in_context.py "$DENSE_RUN_DIR"
# Paired exact McNemar for the turn-AIC gap.
python scripts/aic_mcnemar.py
The sidecar requires the local dataset and run manifests. Embedding-mode replay uses the same query-embedding path as the published run, but it makes no reader call. The McNemar script reads the per-question AIC vectors produced by the scorer and performs exact binomial McNemar on the paired hit/miss vectors.
Any retrieval-behavior PR, including global temporal expansion or altered packing, should either be default-off or explicitly labeled as vNext so the repo and post remain in lockstep.
Follow-up work this invites
The follow-up this most naturally invites - for me or for anyone else using the harness - is a semantic projection benchmark: ingest conversations into explicit typed objects such as people, facts, events, dates, preferences, contradictions, updates, and provenance links, then test whether that improves the categories where deterministic retrieval leaves room.
The AIC results make the hypotheses more specific:
- Knowledge-update should improve only if semantic projection marks facts as superseded before assembly and makes reconciliation easier for the reader. Retrieval recall is already near ceiling there - roughly 95% turn-AIC and roughly 99% session-AIC for both systems - so LongMemEval-S structurally cannot tell whether typed superseded-fact representation helps. The bottleneck it would address is reader reconciliation, not retrieval.
- Temporal-reasoning could improve because dated events can be normalized and selected at turn level instead of rediscovered from prose.
- Multi-session reasoning could improve because cross-session entities and facts can be linked before retrieval, helping the system find the exact evidence turns rather than merely the right sessions.
- Replayability and auditability should remain inspectable if extraction outputs are written as events.
That would be the real ActiveGraph semantic-memory test. This run does not answer it. It establishes the baseline: deterministic evidence compilation is not obviously a retrieval tax, so the next test can ask whether semantic projection adds anything beyond a capable substrate.
References and public comparison sources
- Di Wu et al., LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR 2025.
- LongMemEval official repository: https://github.com/xiaowu0162/longmemeval.
- LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues, 2026.
- Yohei Nakajima, The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems, 2026.
- ActiveGraph benchmark harness: https://github.com/yoheinakajima/activegraph-longmemeval.
- ActiveGraph original QA benchmark release: https://github.com/yoheinakajima/activegraph-longmemeval/releases/tag/v0.1-paper-longmemeval-s.
- ActiveGraph answer-in-context release: https://github.com/yoheinakajima/activegraph-longmemeval/releases/tag/v0.2-paper-longmemeval-s.
- ActiveGraph answer-in-context significance release: https://github.com/yoheinakajima/activegraph-longmemeval/releases/tag/v0.2.1-paper-longmemeval-s.
- ActiveGraph answer-in-context results: https://github.com/yoheinakajima/activegraph-longmemeval/blob/main/paper/aic_results.md.
- MindGraph repository: https://github.com/yoheinakajima/mindgraph.
- Haoyu Han et al., RAG vs. GraphRAG: A Systematic Evaluation and Key Insights, 2025.
- Is Grep All You Need? How Agent Harnesses Reshape Agentic Search, 2026.
- SmartSearch, How Ranking Beats Structure for Conversational Memory Retrieval, 2026.
- Mastra, Observational Memory: 95% on LongMemEval and Observational Memory docs.
- Mem0, Benchmarking Mem0's token-efficient memory algorithm.
- Memanto, Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents.
- True Memory, Storage Is Not Memory: A Retrieval-Centered Architecture for Agent Recall.
- Vectorize, Hindsight: Building Agent Memory that Retains, Recalls, and Reflects.
- Memory survey: Memory in the Age of AI Agents.
- Backboard, Backboard LongMemEval results.
← back to blog