Introducing learn.activegraph.ai
A new site for activegraph that teaches the framework as a refactor: start from the while-loop agent everyone has built, substitute one piece at a time, and end up at an event-sourced graph runtime with replay, provenance, contradictions, and forkable conclusions.
- learn
- teaching
- announcement
activegraph already had two sites. activegraph.ai is the pitch. docs.activegraph.ai is the reference. As of this week there's a third one: learn.activegraph.ai.
I wanted a different surface because docs only help once you already know what you're looking for. They tell you the signature of Runtime.fork, the event types the runtime emits, the contract a behavior honors. They don't tell you why any of it exists, or why you'd pick activegraph over a while loop and a list of messages.
That "why" is what learn is for.
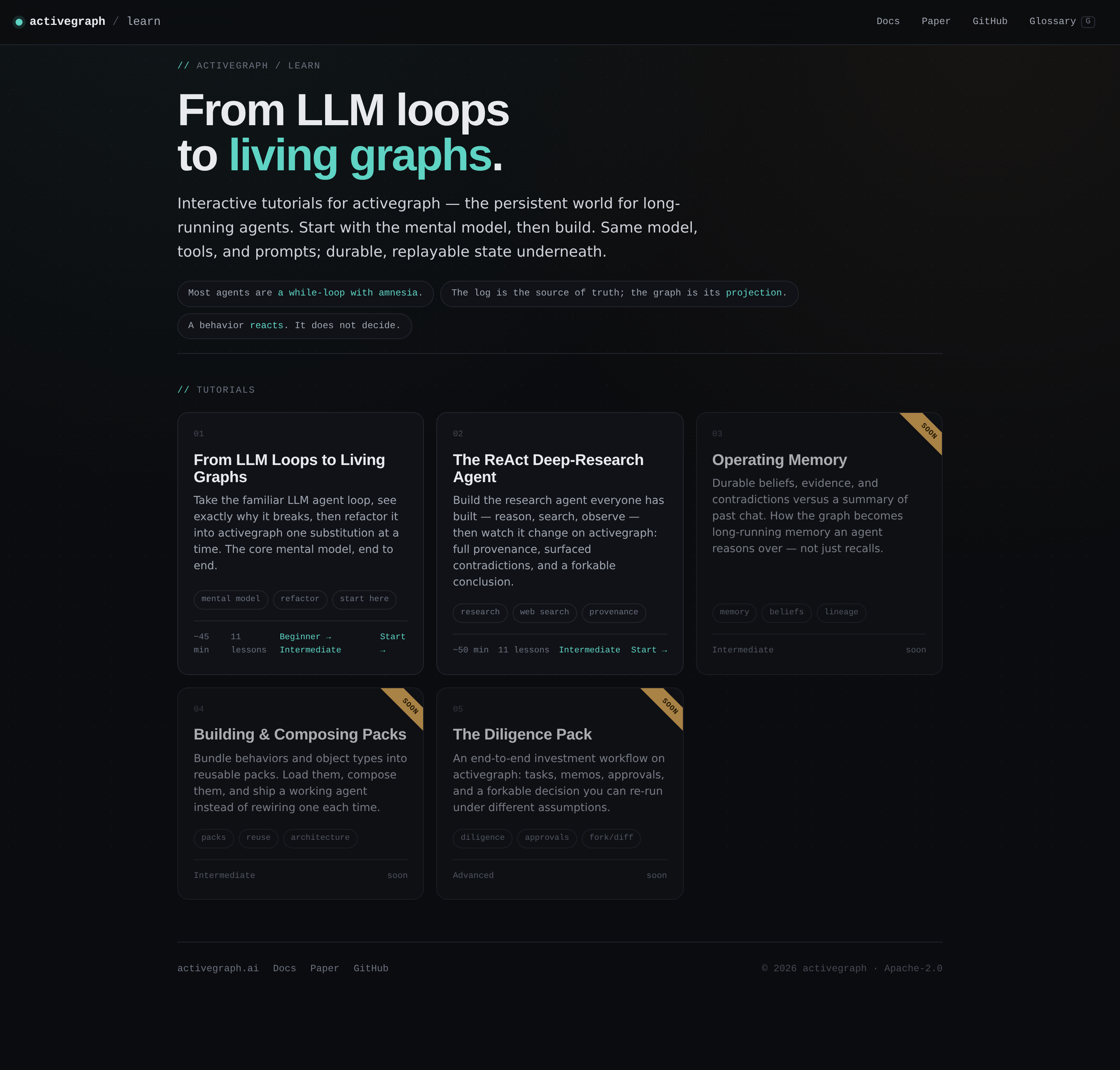
Teach it as a refactor
Most tutorials for a new framework spend the first half on vocabulary. Here are nodes. Here are edges. Here are events. Behaviors. Tools. Packs. By the time you finish you've learned a lot of words and still don't really know what changed.
So I tried something different. Every lesson starts from the agent you've already built, the while loop with the list of messages, and refactors it into activegraph one step at a time. New vocabulary only shows up when it has to.
The first tutorial, From LLM Loops to Living Graphs, is exactly that refactor. Four substitutions:
messages[]becomes an append-only event log.- Parsed strings become a typed graph projected from that log.
- The master
whileloop becomes behaviors reacting to events. - The log persists, so the whole run replays from disk.
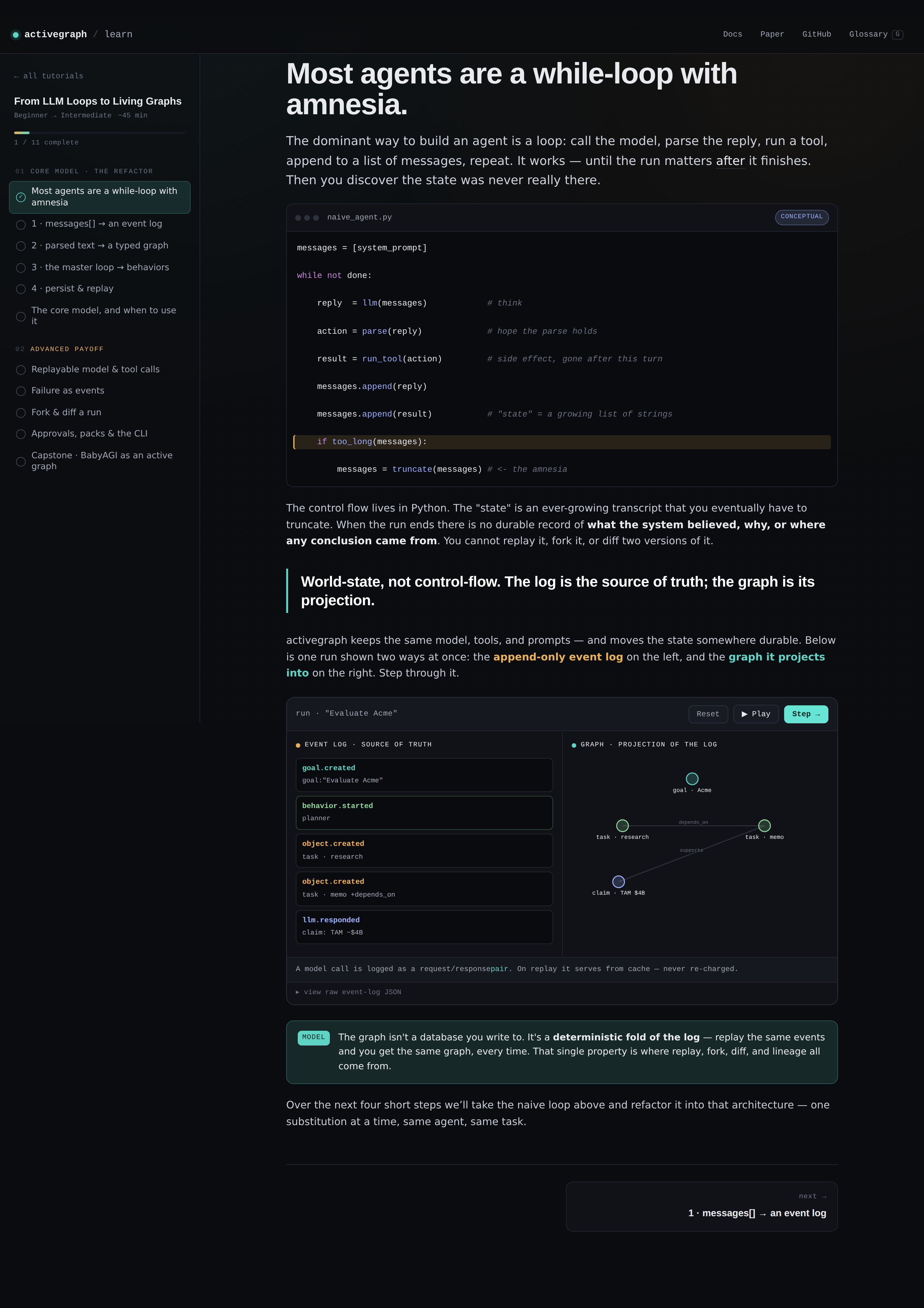
The whole thing is interactive. You step through the same run two ways at once. Event log on one side. Graph on the other. The thing you're learning about is also the thing you're looking at, which I think is just the right way to teach this stuff.
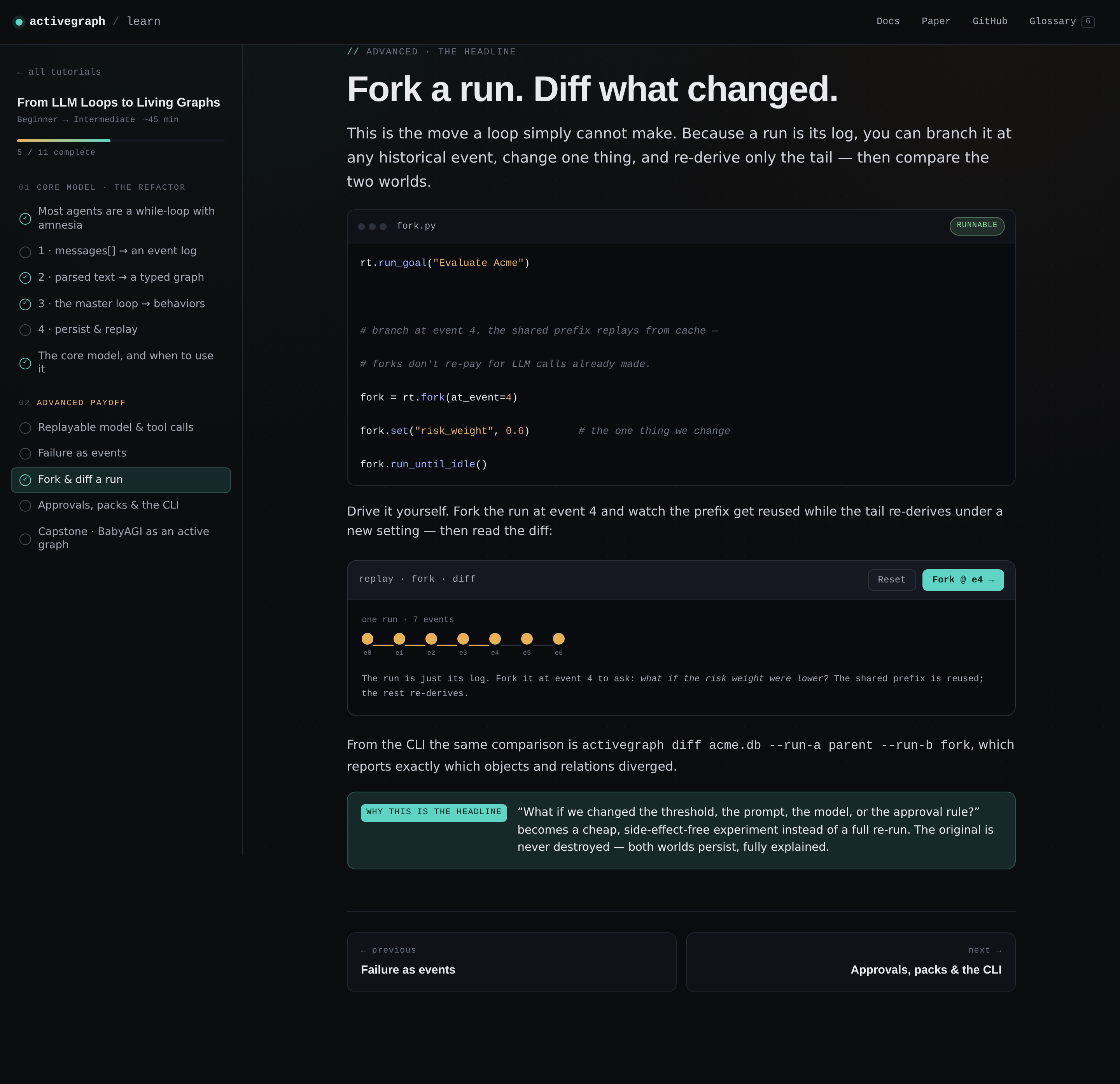
By lesson five the refactor is done. The naive loop is gone. What's left is the architecture activegraph actually runs on. From there the advanced track shows what the substrate gives you that a loop never could: replayable model and tool calls, failure as events instead of exceptions, and the move I think actually sells the framework, which is forking a finished run at a historical event and diffing the two worlds.
Research is the harder demo
A diagram of an event-sourced agent is convincing. A worked example is more convincing.
So for the second tutorial I picked the worked example carefully. Everyone has built a ReAct deep-research agent by now. Reason, act, observe, append to scratchpad, repeat. It demos beautifully. It also fails in exactly the ways research can't tolerate. The scratchpad summarizes its sources away. The model silently picks one of two conflicting numbers. You can't re-ask the run under a different policy without re-paying for every search.
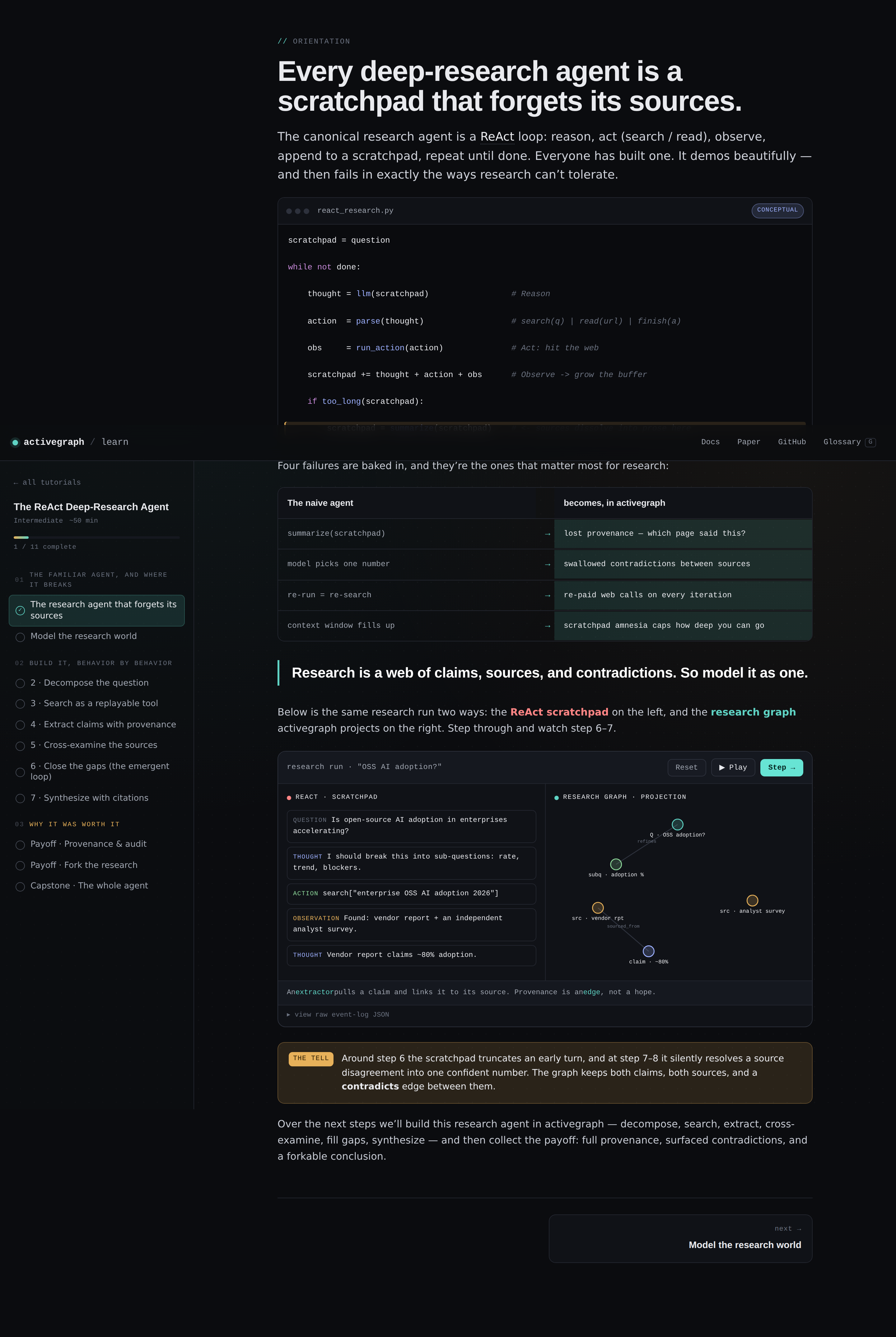
So we rebuild that agent on activegraph in The ReAct Deep-Research Agent, behavior by behavior. Three things fall out that you can't get from a loop.
Contradictions become facts. When two sources disagree, a small behavior watching for that pattern emits a contradicts edge. The synthesizer reads the graph and reports the conflict. The scratchpad version silently picked one number.
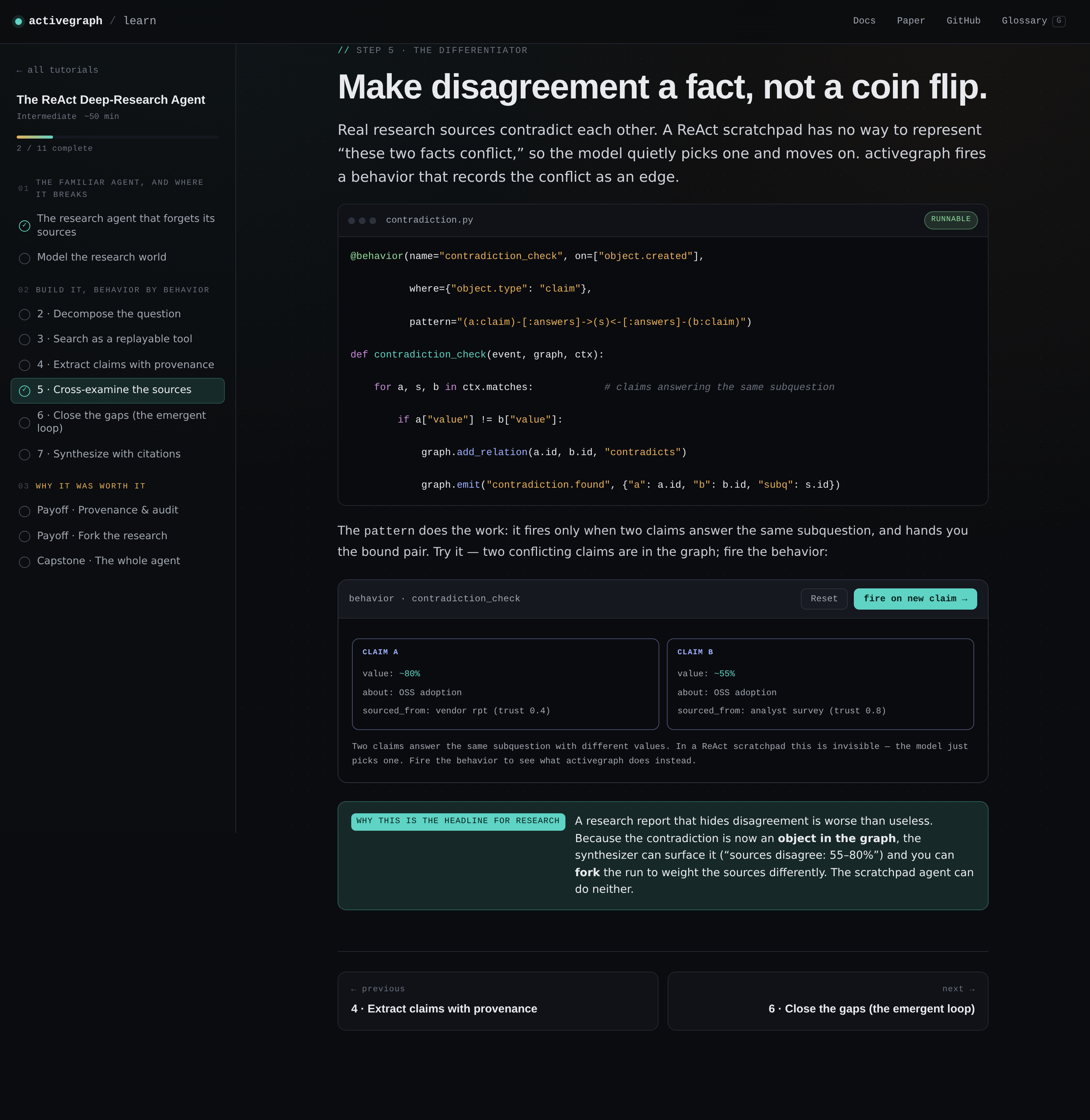
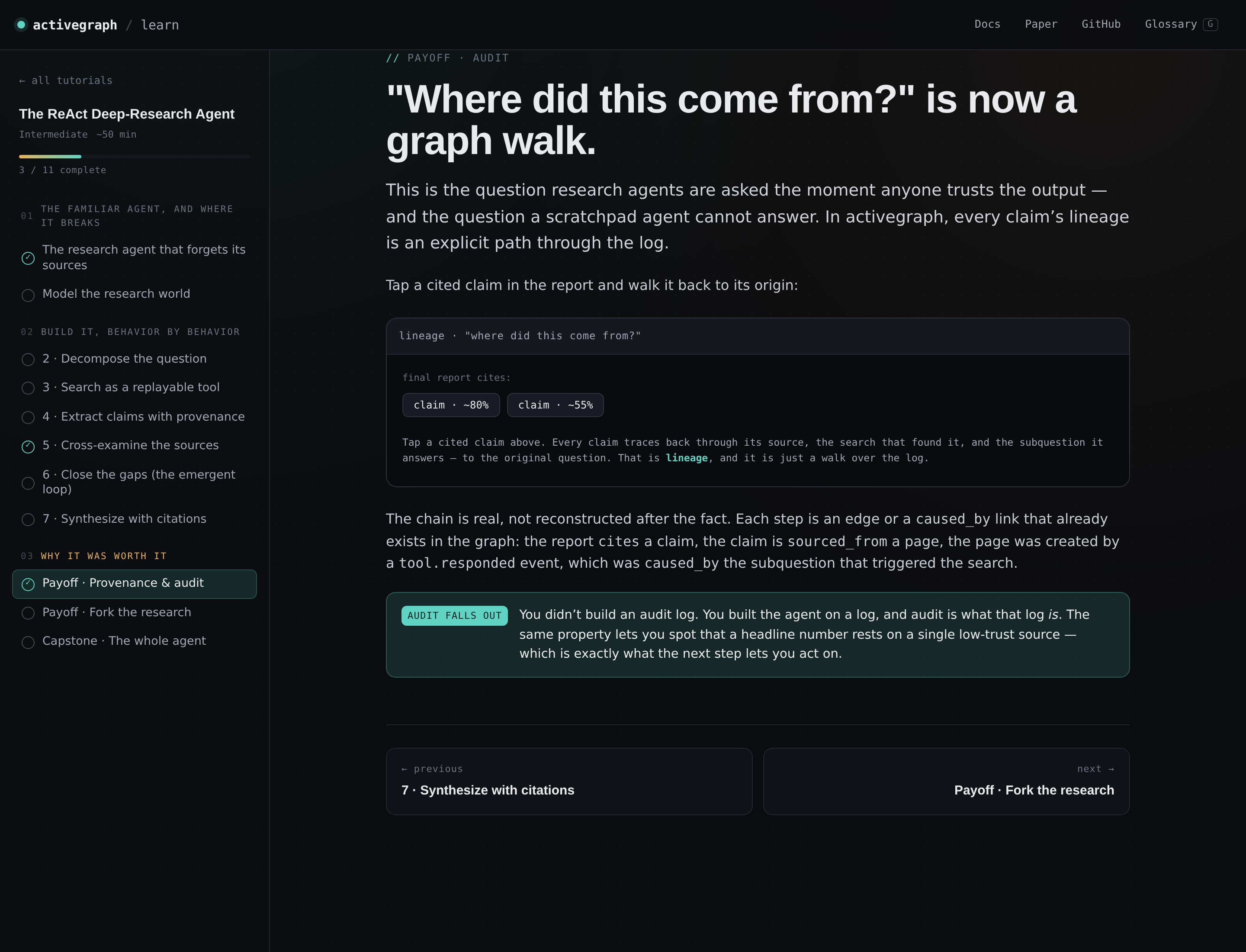
Provenance is a graph walk. Tap any claim in the final report. Walk it back through sourced_from and caused_by edges, all the way to the search query and the question it answers. It isn't reconstructed after the fact. It was always in the graph.
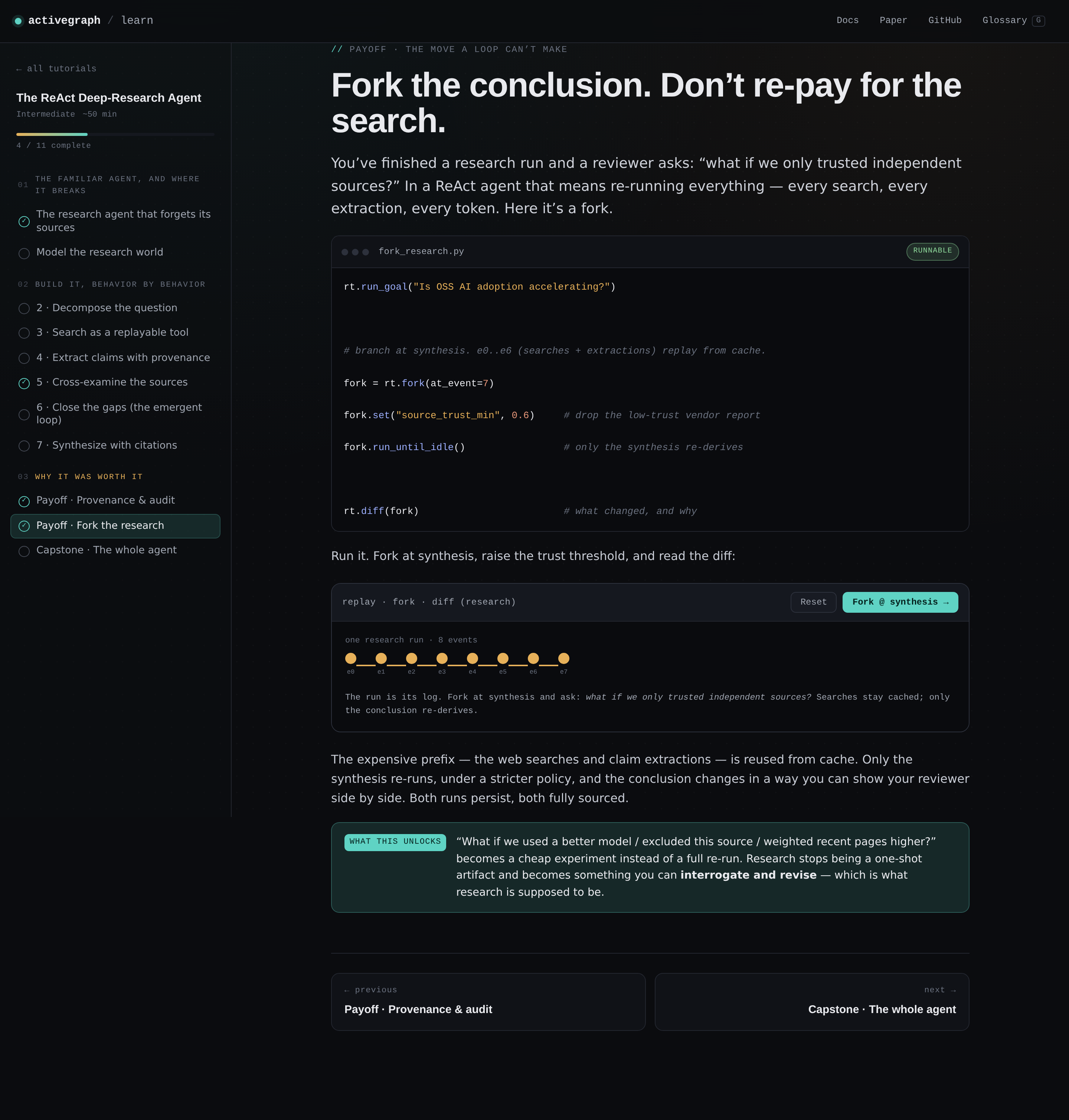
You can fork the conclusion without re-paying for the searches. A reviewer asks "rerun this trusting only independent sources." The expensive prefix replays from cache. Only the synthesis re-derives. Both worlds persist, side by side, fully sourced.
The framing I used internally was: research is a web of claims, sources, and contradictions, so model it as one. I think the tutorial earns that line.
How I built it
The site itself follows the same principle as the framework it teaches. Keep the substrate honest and the rest falls out.
It's a static, zero-build, zero-dependency SPA. No npm tree, no bundler, no transpile. Plain ES modules served from GitHub Pages. Every "page" renders client-side from JavaScript data. Adding a tutorial is one new file plus one line in a registry. The whole runtime is small enough to read in an afternoon.
I did it this way for the same reason the runtime is event-sourced. It can't rot. In five years index.html still opens. There's no framework major version waiting to break it.
The content came together with Claude over three sessions. The first produced the initial site, a single 1,500-line HTML draft with all the interactive sims working end to end. The second pulled in the activegraph.ai brand, narrowed the arc into Core then Advanced, and split the monolith into modules. The third added the ReAct research tutorial. A fourth, much shorter session wired up GitHub Pages.
Working this way, with a model that can hold the architecture and the lesson copy at the same time, meant I could write a tutorial and design the interactive widget for that tutorial in the same conversation. The sims aren't decorative. They are the lesson. I wouldn't have built them otherwise.
What's next
Three more tutorials are stubbed on the home page and will follow:
- Operating Memory. Durable beliefs, evidence, and contradictions in place of a summary of past chat.
- Building & Composing Packs. Bundle behaviors and object types into reusable units. Load one, get a working agent.
- The Diligence Pack. An end-to-end investment workflow on activegraph: tasks, memos, approvals, a forkable decision.
The vocabulary will keep growing. The shape won't. Every lesson is a refactor. Start with the agent everyone has built. Move one piece. See what changed.
← back to blog