Self-Modification Is Not Binary
Typed, auditable self-change on an event-sourced agent runtime
- self-modification
- event-sourcing
- selfgraph
- activegraph
In most agent architectures, "self-modification" is treated as a binary property: either the agent modified itself or it didn't. Usually the word is reserved for an exceptional, privileged act — rewriting code, editing a system prompt, mutating a hidden runtime registry — set apart from ordinary operation. This framing is a trap, because it makes the interesting question disappear.
A long-running agent changes itself whenever it durably changes the state from which its future behavior is projected. It remembers a fact. It creates a task. It records a policy. It stores a tool result. It binds a behavior to a new context. Each of these changes can alter what the agent later sees, retrieves, prioritizes, or does. In most systems these durable changes are scattered across representational layers — prompts, tool registries, memory stores, configuration, logs, code. The scatter is what makes "self-modification" feel like a category apart: the change reaches into a privileged layer that the agent's ordinary operational history doesn't touch.
This post is a companion to The Log is the Agent, which introduced ActiveGraph's event-sourced runtime: the append-only log is the source of truth, the working graph is a deterministic projection of that log, and behaviors react to graph changes by emitting further events. Under this substrate, those scattered representational layers collapse. A task, a policy, an evaluation, an object type, a relation, a behavior binding — each is a logged mutation to the graph from which the agent's future state is projected. Durable operation and self-change occupy the same representational category.
That collapse changes the question. It is no longer did the agent modify itself — because under this view, every durable action does, in a weak but literal sense. The question becomes what kind of self-change occurred, what future behavior can it affect, and can it be forked, diffed, promoted, replayed, or reversed?
The short version.
- Self-change is any durable mutation to the graph from which future agent state is projected. Under event sourcing, ordinary operation already does this.
- Self-modification is the narrower subset that alters configuration, governance, domain model, or behavior.
- Behavioral self-modification is narrower still: changes that alter which behavior can fire in response to future events.
- selfgraph shows this can be represented as typed graph patches, evaluated in forks, structurally diffed, and promoted only through logged events — bounded self-change with an inspectable lifecycle.
This post introduces selfgraph, a minimal ActiveGraph agent that exposes those questions empirically. It ingests its own runtime, constructs a capability graph from discovered APIs, types, behaviors, and constraints, and proposes bounded changes to its own operating graph. Each proposal is a typed graph patch, evaluated in a fork, structurally diffed, and promoted only through logged events. selfgraph deliberately excludes authored executable code — its action space is restricted to seven typed graph operations, which is a methodological choice the closing section returns to. The measured loop is also deliberately model-free: extraction, proposal generation, validation, sandboxing, diffing, and promotion make no model calls. That makes selfgraph less capable than an LLM-driven proposer would be, and is the point — it isolates the substrate lifecycle from proposal quality so the two can be evaluated separately. The goal is to study the lifecycle of self-change before adding either generated code or model-driven proposal generation.
selfgraph and PatchProposal #578
The concrete case is easier than the abstract definition. Given the goal "monitor company," selfgraph produced PatchProposal #578. The proposal was grounded in the runtime object type company, which the agent had discovered by extracting object-type declarations from its own source. The proposal contained eight changes, applied first in a fork, structurally diffed against the live graph, and held inert until promotion.
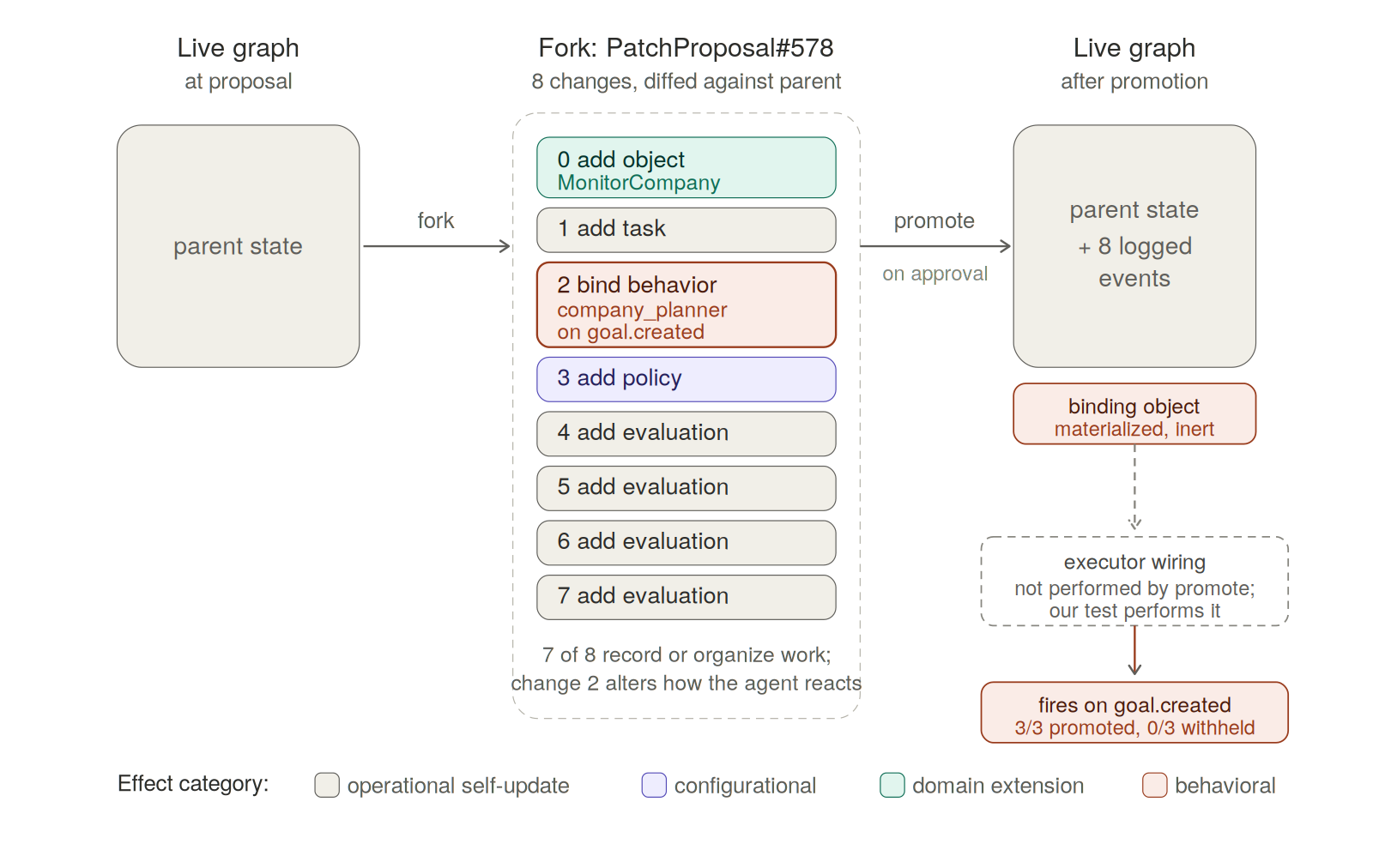
The eight changes break down as follows:
| # | Change | Effect category |
|---|---|---|
| 0 | Add object: MonitorCompany | Domain extension |
| 1 | Add task | Operational self-update |
| 2 | Bind behavior: company_planner on goal.created, scoped to MonitorCompany | Behavioral self-modification |
| 3 | Add policy | Configurational self-modification |
| 4–7 | Add evaluation criteria (×4) | Operational self-update |
All eight changes are self-change in the substrate sense — every one is a durable mutation to the graph from which the agent's future state is projected. But only change 2 alters what the agent can do next: it binds an existing behavior, company_planner, to a new event pattern and scope. The other seven record, organize, evaluate, or govern future work; they shape the conditions under which behavior occurs without adding new reactivity.
That distinction — between durable change and behavior-changing durable change — is the whole conceptual move. PatchProposal #578 makes it visible because every kind of self-change shows up in the same proposal, represented as graph state, attributable by provenance, and inspectable in the same fork. In a conventional architecture each row of that table would live in a different system layer, and "did the agent modify itself" would have a different answer depending on which row you looked at.
When the proposal was promoted, the binding object was materialized as logged graph state. After the binding was wired by the executor, emitting a matching goal.created event caused company_planner to fire; withholding promotion left it silent. Across three distinct bound behaviors, promoted bindings fired in 3 of 3 trials and withheld bindings fired in 0 of 3 trials.
One implementation qualification matters here, because it bears on later claims. Promotion materializes the binding object as an event on the log, but final runtime registration — the step that actually wires the bound behavior into the dispatcher — is performed by a separate executor that the test harness invokes. The binding declaration carries the information needed for that wiring step, but the measured implementation does not yet complete end-to-end registration through promotion alone. Closing that gap is a natural next increment; it doesn't change the central claim about the lifecycle, but it does mean the 3-of-3-versus-0-of-3 result is partly a property of the harness, not of the substrate end-to-end.
A taxonomy over measured provenance
The categories in the #578 table — operational, configurational, domain extension, behavioral — aren't features the runtime distinguishes intrinsically. On an event-sourced graph substrate, every graph mutation is the same kind of object. The taxonomy is an analytical lens, applied by reading provenance and inferring likely future effect:
-
Operational self-update — durable changes that record, organize, or evaluate work: task objects, traces, evaluation criteria, output records. These become future context; they don't directly alter which behaviors fire.
-
Configurational self-modification — changes to the operating structure under which future work occurs: policies, scopes, constraints, state buckets, evaluation regimes. These shape the conditions for future operation without adding behavior.
-
Domain extension — additions to the model of the world the agent operates over: new object types, goal-derived state objects, relations. They expand the state space the agent can perceive and operate on.
-
Behavioral self-modification — the narrowest and strongest case: changes that alter how the agent reacts to future events. In selfgraph this happens through behavior bindings, which can only reference behaviors the agent has already discovered in its capability graph.
In PatchProposal #578, changes 0 through 7 distribute across all four categories. That distribution isn't random; it's the natural shape of self-change for a long-running agent. Bookkeeping, governance, domain extension, and behavior modification show up together because they're how durable agent state actually grows.
Measurement note. What the runtime measures directly is provenance — the origin of each change (built-in scaffold, self-authored proposal structure, domain-derived, grounded in a discovered runtime primitive). The four effect categories above are an interpretation of those provenance counts by their likely graph effect. They aren't a second independent measurement. The provenance distribution we report below is real; the mapping to effect categories is analytical and should be read as such.
Results: lifecycle validation and the shape of self-change
We ran selfgraph across two corpus conditions, sized for the questions each was designed to answer.
Lifecycle validation: 117 proposals. The first condition tested whether the substrate behaves as promised — whether forks isolate the live graph, whether the action space rejects out-of-space proposals, whether promotion is a separate event from proposal. Across 117 proposals, every fork preserved the live graph until promotion. Object counts, relation counts, and event counts in the live graph were unchanged after sandbox evaluation when promotion was withheld. Adversarial proposals deliberately constructed outside the seven-operation action space were rejected by construction: 28 of 28 adversarial cases were rejected, 45 of 45 benign cases passed. This is necessary validation, not a surprising result — it confirms that selfgraph's self-change proposals actually enter the lifecycle the architecture claims rather than bypassing it.
Self-change composition: 72 richer proposals. The second condition asked the more substantive question: what does self-change look like when the action space is exercised across a richer goal set? Across 72 proposals, selfgraph emitted 747 total changes, distributed by provenance origin as follows:
| Provenance origin | Share | Effect-category interpretation |
|---|---|---|
| Self-authored proposal structure | 57.8% | Mostly operational and configurational self-change |
| Domain-new | 18.1% | Domain extension |
| Built-in scaffold | 16.9% | Scaffolded operational/configurational structure |
| Grounded-in-discovered-primitive | 7.2% | Runtime-grounded changes, including behavior bindings |
Behavioral self-modification occurred in 9 of 72 proposals. In every case, it happened by binding a behavior that already existed in the capability graph — selfgraph never authored a new behavior. It reconfigured discovered behaviors into new operating contexts. This is not a negative result. It's the anatomy of bounded self-change in a system that deliberately excludes authored code: most durable mutations are operational and structural, with behavior-changing mutations as a smaller, runtime-grounded subset. The substrate makes that distribution measurable rather than leaving it implicit.
The lever experiment
The most informative result isn't that 9 proposals bound behaviors. It's why behavior binding appeared only after a self-discovery bottleneck was removed.
selfgraph can modify itself behaviorally only in terms of runtime capabilities it has discovered and represented in its capability graph. If a behavior exists in the runtime but isn't extracted, the proposer cannot reference it. If an object type exists but isn't represented, goals derived from that object type cannot be generated or grounded. The agent's self-model of its own runtime bounds what self-modification it can express.
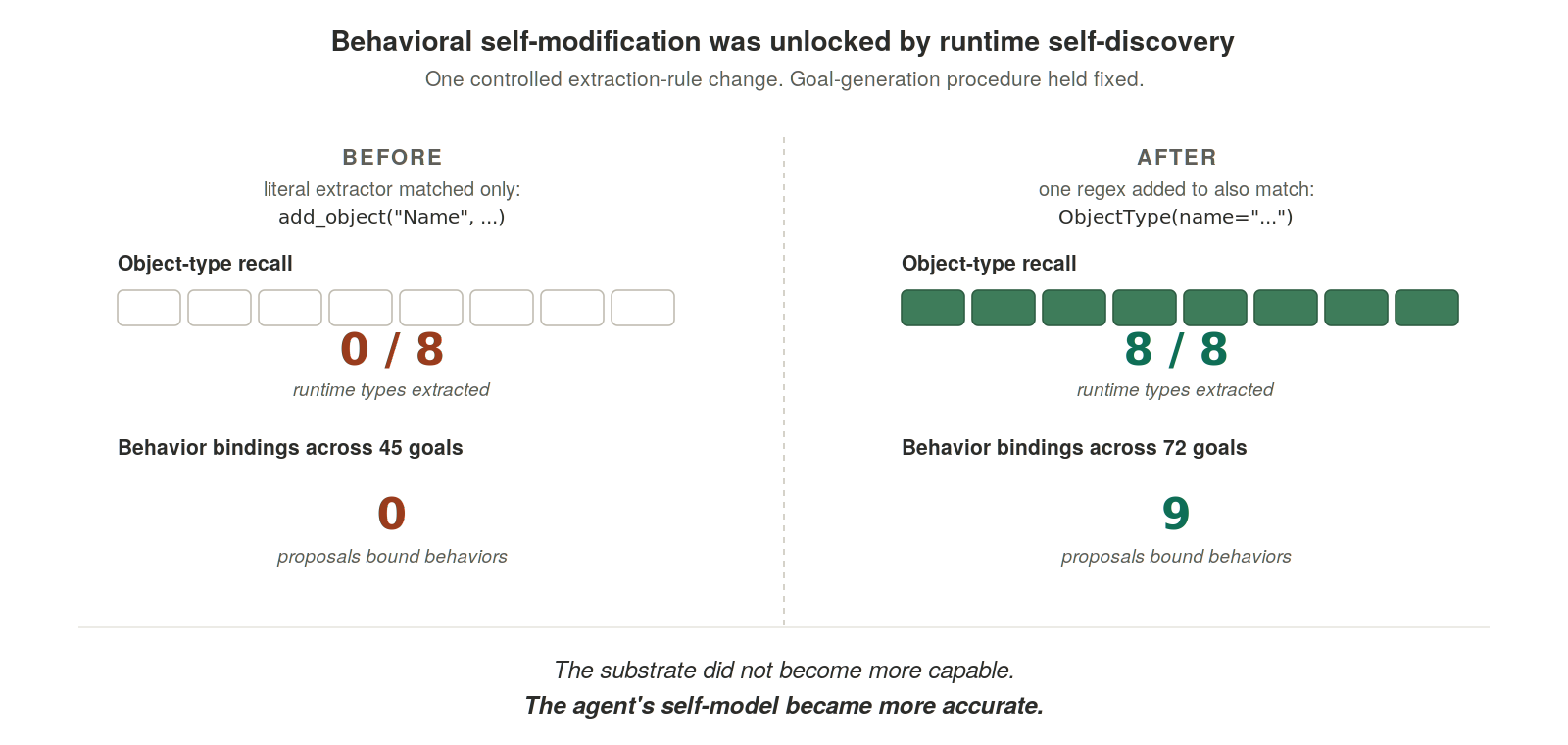
The original object-type extractor recognized declarations whose captured names began with a capital letter — the form add_object("Name", ...) that selfgraph uses in its own source. But ActiveGraph runtime object types were declared through constructor calls like ObjectType(name="company"), with lowercase quoted names. The capital-letter requirement excluded all of them. The extractor matched zero of the eight runtime object-type declarations.
We made one controlled change: added a regex that recognizes the ObjectType(name="...") constructor form. The goal-generation procedure was held fixed. The original 45 goals were unchanged across both conditions, and their grounding rate stayed at 27 of 45.
The effect was sharp. Runtime object-type recall moved from 0 of 8 to 8 of 8. The goal corpus expanded from 45 to 72, with 27 new goals derived from the newly visible runtime types. Behavioral self-modification, which had occurred in zero proposals under the literal extractor, now occurred in 9 proposals. The change is causally attributable to runtime object-type visibility, not to any change in proposer behavior.
The substrate did not become more capable. The agent's self-model became more accurate.
Runtime self-discovery also bounded the result from above. Behavior recall remained at 3 of 7 under both extractor settings. The four missed behaviors shared a single cause: their decorators contained nested-parenthesis arguments like pattern=(...), tools=[fn(...)], or budget={...}, and the extractor's flat character-class body terminated at the first inner parenthesis and therefore failed to parse those decorators. The three behaviors selfgraph successfully bound were exactly the three the extractor could see — company_planner, evidence_linker, question_generator — and the four it never bound were exactly the four the extractor could not parse.
This is the core lesson of the experiment. Behavioral self-modification is bounded by the agent's model of its own runtime. An agent cannot use what it cannot see, cannot ground in capabilities it has not represented, cannot bind behaviors absent from its capability graph. The substrate makes change inspectable; runtime self-discovery determines what change is reachable at all.
What this does and does not claim
The substantive claims are narrower than the prose around self-modifying agents usually carries:
- Substrate lifecycle. Within the seven-operation action space, proposed self-changes are structurally contained, evaluated in forks, diffed against the parent graph, and promoted as replayable events. Adversarial proposals outside the action space are rejected by construction.
- Composition is measurable. Self-change can be classified by provenance directly, and by likely effect as an interpretation of that provenance — the substrate exposes both layers, where conventional architectures expose neither.
- Self-discovery bounds behavioral self-modification. When the agent's representation of its own runtime is incomplete, the action space narrows to whatever portion is visible.
The disclaimers are equally explicit. We do not claim open-ended self-improvement: selfgraph's action space is deliberately low-expressivity, and behavior binding alone cannot produce arbitrary new capability. We do not claim task-performance gains: this work measures the lifecycle and composition of self-change, not whether the agent gets better at downstream tasks. We do not claim safe authoring of generated code: the action space excludes authored executable behavior entirely; that's the next tier, addressed separately. We do not claim the effect categories are an independent measurement: they are an interpretation of measured provenance, useful as a lens, not a validated semantic classifier. And the promotion → registration step is not yet end-to-end in the runtime: promotion materializes the binding object on the log, but final dispatcher wiring is currently performed by a separate executor invoked by the test harness. Closing that gap is a natural next implementation step; doing it would strengthen the behavioral-self-modification result from "3 of 3 fired post-promotion" toward "fired via the substrate alone."
These bounds aren't decorative caution. They mark exactly where the substrate has been validated and exactly where future work begins.
Where this sits
selfgraph occupies a deliberately low-expressivity point in a fast-moving design space, and the relationships to adjacent work are worth naming explicitly.
Event-sourced and persistent-agent substrates. selfgraph builds directly on ActiveGraph's substrate, where the append-only event log is the source of truth and the working graph is a deterministic projection of that log. The broader event-sourced agent line shares this concern with durable history, replay, and recovery: ESAA (dos Santos Filho, 2026) applies event sourcing to autonomous agents in software-engineering workflows, separating probabilistic intention from deterministic project mutation; Springdrift (Brady, 2026) studies auditable persistent runtimes for long-lived agents with memory, recovery, and self-perception. selfgraph narrows the substrate question to the agent's own operating graph — tasks, policies, state buckets, object types, relations, evaluations, and behavior bindings. The point isn't only that task history can be audited; it's that proposed changes to the agent's own configuration and behavior can be represented as first-class event-sourced artifacts and inspected the same way.
Self-modifying and self-improving agents. A separate line widens the action space toward code-level self-change. The Gödel Machine (Schmidhuber, 2007) proposed self-referential agents that rewrite themselves only after proving improvement. Modern systems replace proof with empirical validation: the Darwin Gödel Machine (Zhang et al., 2025) iteratively modifies its own codebase and validates capability gains on coding benchmarks, and SICA (Robeyns et al., 2025) demonstrates an LLM coding agent autonomously editing its own implementation for measurable benchmark gains. Recent risk work — Misevolution (Shao et al., 2025) — argues that self-evolving agents can develop unintended behaviors precisely because the substrate doesn't expose what changed. selfgraph sits at the opposite end of the expressivity axis. It excludes authored executable code and studies typed graph-native self-change before code enters the action space. The contrast is expressivity versus governability: broad code rewriting can represent many improvements but expands the authority surface; typed graph patches limit what can be expressed so that fork, diff, provenance, promotion, and replay can be measured cleanly.
Executable artifacts and persistent skills as the next tier. Agent research is steadily moving toward persistent executable artifacts: CodeAct (Wang et al., 2024) uses executable Python as a unified action space; LATM (Cai et al., 2023) treats tool-making as a functional cache where one model creates reusable tools for another; Voyager (Wang et al., 2023) accumulates executable skill libraries in open-ended exploration. These systems establish that generated executable artifacts can be powerful — and that artifacts which persist, get selected, get bound to events, also affect the agent's future operating surface. selfgraph stops before that boundary: it only binds behaviors the agent has already discovered in its capability graph. That deliberate stopping point names an open problem the substrate sets up but does not yet solve. When an agent authors new behavior source, when should that generated artifact receive authority to affect the live runtime? Same lifecycle, wider action space — and a real authorization boundary to draw between proposal and live behavior.
What this is, and what's left
selfgraph is not a powerful self-improving agent. It is a constrained experiment showing that self-change — in a deliberately low-expressivity action space — can be made visible, typed, forkable, diffable, promotable, replayable, and reversible. That is the first tier of an agenda about long-running self-building agents, and it leaves real work for the tiers above it.
The most important thing selfgraph deliberately doesn't do is author executable code. Its action space stops at typed graph mutation and bindings to already-discovered behaviors. The reason for that exclusion is methodological: starting with a low-expressivity action space lets the lifecycle of self-change — proposal, fork, diff, promotion, replay, rollback, classification — be studied without conflating it with code-generation quality or arbitrary execution safety. Code authoring is a real next tier. And the more LLM agents move toward generating executable artifacts — code actions, persistent skills, behavioral routines — the more pressing it becomes to draw a clean line between generating code and granting code authority over the live runtime. A model may write a behavior, but that doesn't mean the behavior should immediately become part of how the agent acts. The model may be wrong, underspecified, semantically mismatched to the intended graph effect, or simply not what the runtime should be authorized to execute next. The same lifecycle this post describes — proposal as event-sourced state, validation in a fork, structural diff, promotion as a distinct event — extends naturally to authored behavior source; the action space widens, the authority boundary stays in the same place. That extension is work in progress, addressed elsewhere.
What selfgraph demonstrates standalone is narrower and worth stating directly: an agent's self-change can be represented as first-class event-sourced state and inspected the same way the agent's ordinary operation is inspected; the four-way taxonomy of operational, configurational, domain-extending, and behavioral self-modification is meaningful in proportion, even when read as an interpretation of measured provenance; and behavioral self-modification is bounded above by the accuracy of the agent's self-model, which a single regex change made visible in the lever experiment. The substrate didn't become more capable. The agent's self-model became more accurate. That is the kind of result the substrate makes measurable, and it's the kind of result long-running self-building agents need to be legible at all.
Code and reproduction artifacts (Apache-2.0): github.com/yoheinakajima/activegraph-selfgraph (v1.0.0). Install with pip install -r requirements.txt and run python demo.py. The measured results are deterministic and require no API key; an optional LLM extraction pass is additive only and was disabled for every measurement here.
← back to blog