Code Without Authority
An authority lifecycle for generated behavior in an event-sourced agent runtime
- self-modification
- event-sourcing
- selfgraph
- behavior-drafts
- activegraph
Generated code is not the same as authorized behavior.
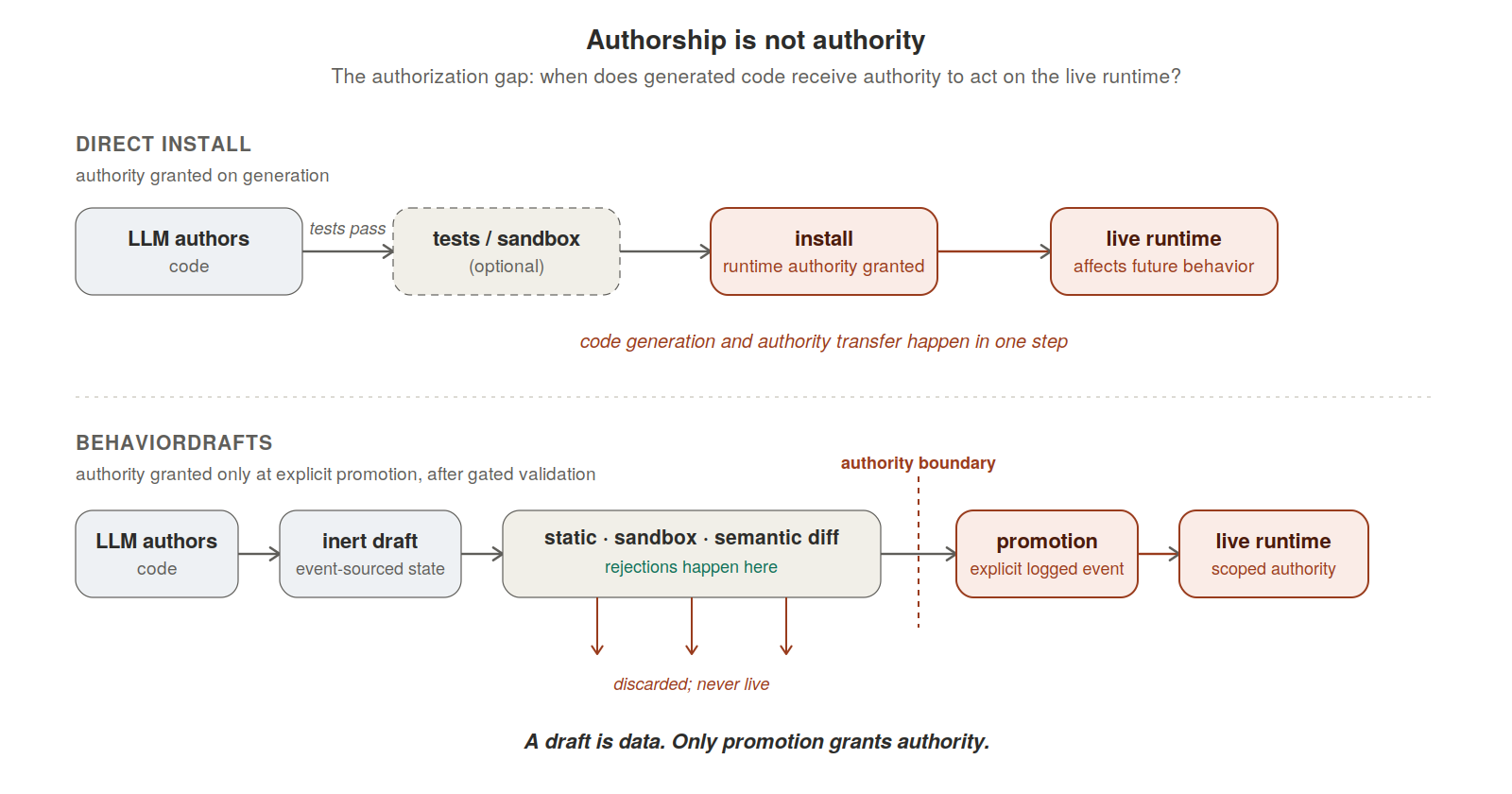
That distinction is easy to miss because so many systems blur it. A model writes code; the system runs it; if the tests pass, the code becomes part of the runtime. The pipeline reads as a single act, but it conflates two operations that are different in kind. Generating code is the model proposing something. Granting code authority over the live runtime is the system accepting that proposal. The first should not automatically imply the second.
LLM agents are increasingly producing executable artifacts — code actions, persistent skills, behavioral routines, in some systems modifications to their own codebases. As soon as such artifacts become persistent and executable, they affect the agent's future behavior. They define how the agent reacts to events, what objects it creates, what relations it asserts, what policies it enforces. The model that wrote them may have been wrong, underspecified, semantically mismatched to the intended effect, or merely producing something that happens to execute. None of those failure modes are caught by "the tests passed."
This post introduces BehaviorDrafts, an event-sourced lifecycle for generated behavior code. A BehaviorDraft is a proposed behavior, not a behavior — an inert graph artifact containing source, declared triggers, scope, permissions, tests, provenance, and expected graph effects. Draft creation records a proposal. It does not register an executable behavior. The draft receives runtime authority only after passing static analysis, forked sandbox execution, semantic graph-diff validation, and explicit promotion. The central design principle is code authorship without automatic code authority.
This work follows directly from the selfgraph post on bounded graph-native self-change. selfgraph deliberately excluded authored executable code; it studied the lifecycle of self-change under a low-expressivity action space (typed graph patches, bindings to already-discovered behaviors) so the lifecycle itself could be measured without conflation. BehaviorDrafts widens the action space to authored behavior source while preserving the same event-sourced promotion boundary. The architecture is the same lifecycle. The action space is wider.
The short version.
- The authorization gap is the missing lifecycle boundary between an agent generating an executable artifact and that artifact gaining authority over the live runtime.
- A BehaviorDraft is generated code represented as inert event-sourced state — source, trigger, scope, permissions, tests, provenance — with no authority to execute.
- Promotion is a separate logged event. A draft becomes a live behavior only after passing static, sandbox, and semantic-diff gates. The model never promotes its own code.
- The distinctive gate is semantic graph diff — checking that the behavior produced the intended graph-level effect, not merely that the code ran.
A running example: BehaviorDraft url_extract_1
The lifecycle is easier to see through a single goal from the evaluation corpus. The goal url_extract_1 asks the agent to create a behavior that, when a file object contains a URL, emits a URLFinding object with the extracted URL and links the finding back to the source file. The LLM authors source code; the runtime records it as a draft; the gates decide what happens next.
Each gate asks a different question. Static analysis asks whether the source is structurally allowed — no forbidden imports, no direct graph mutation, no runtime introspection, no dynamic execution. Sandbox execution asks whether the code runs in a forked runtime with a read-only graph and an emit-only context, without crashing or reaching for unavailable builtins. Semantic diff asks the question the other two cannot: did the behavior produce the intended graph-level effect? Right objects, right fields, right relations, right scope, right counts.
url_extract_1 failed in instructive ways across its three trials. Two failures occurred at the sandbox stage because the generated code used the next builtin, which is not exposed in the restricted execution environment — the code parsed fine but couldn't run. One failed at static analysis because the source was malformed. In neither case did the draft become live behavior; in both cases the discard was localized to a specific gate with a recorded reason.
The semantically interesting failure happens in a different goal: rel_summary_source. There the model wrote code that produced an allowed Summary object correctly, but never emitted the relation linking the summary to its source file. The code parsed. It ran. The graph effect was wrong. A sandbox-only promotion policy would have authorized it; semantic diff caught it. That single case — safe-looking executable code with the wrong graph effect — is the entire empirical argument for why sandboxing alone isn't enough.
The lifecycle
A BehaviorDraft moves through six stages. Five of them filter; one is the actual authority transfer.
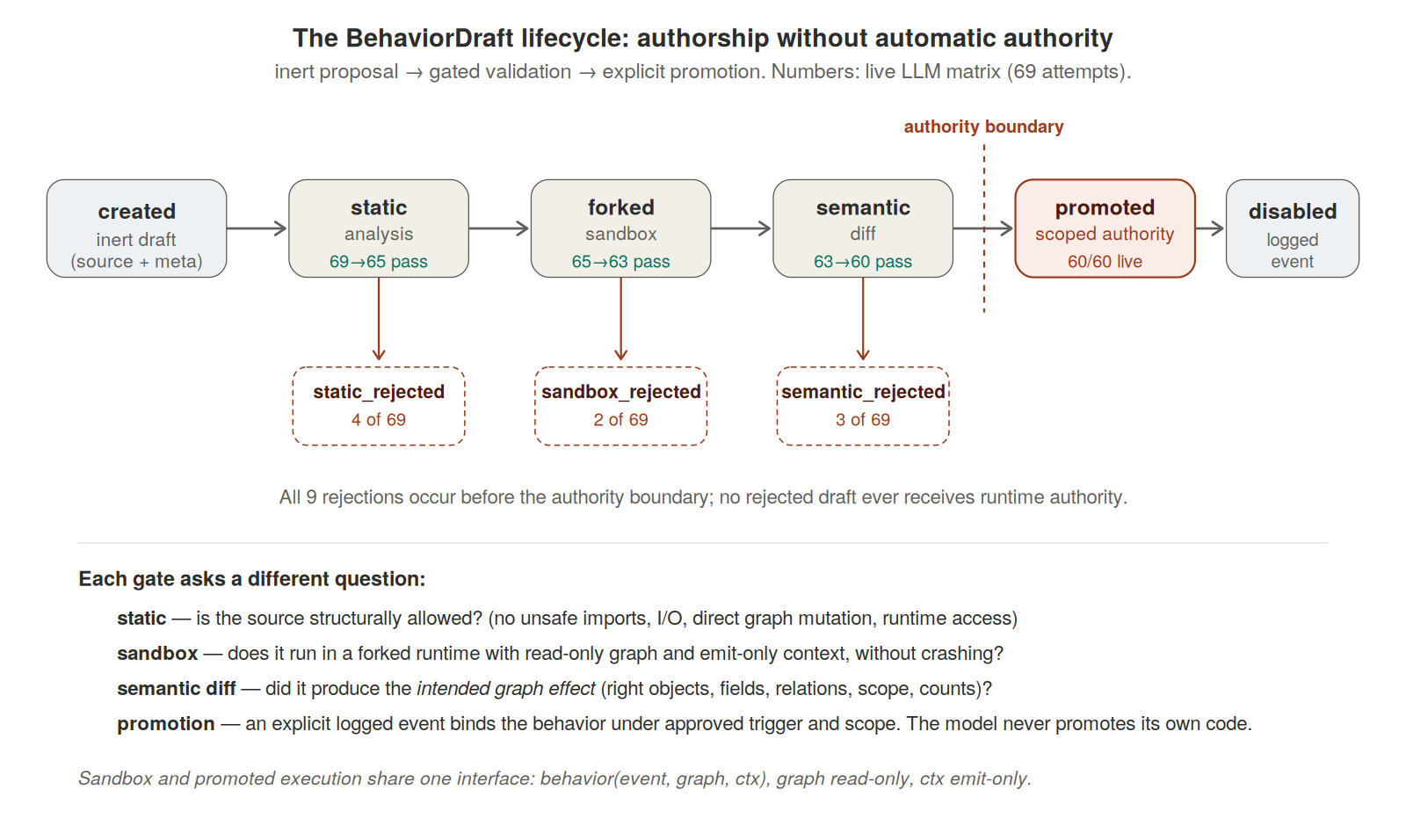
Stage 1 — draft creation. The LLM produces source. The runtime records the source and metadata as an inert graph object. No behavior is registered, no trigger is active, no runtime authority is granted.
Stage 2 — static analysis. Pattern-based and AST-level checks against a fixed policy: parse validity, expected callable shape, no unsafe imports, no filesystem or network access, no runtime introspection, no direct graph mutation, no access to promotion machinery, no dangerous builtins. This is a first gate, not a proof of safety.
Stage 3 — forked sandbox execution. The draft is compiled into a restricted namespace and invoked on controlled fixtures in a forked runtime. The live graph is not touched. Drafts fail here if they crash, exceed execution constraints, use unavailable builtins, or attempt anything outside the constrained interface.
Stage 4 — semantic diff validation. The forked graph effects are compared against goal-specific validators. The validators inspect emitted objects, fields, relations, counts, source links, scope constraints, and expected values. This is the gate that catches behaviors that ran but produced the wrong graph effect.
Stage 5 — promotion. Only after passing all prior gates is a draft eligible for promotion. Promotion binds the behavior into the live runtime under the approved trigger and scope. Promotion itself is a logged event. The model never promotes its own code — promotion is an explicit runtime act.
Stage 6 — disable. A promoted behavior can later be disabled through another logged event. Disablement stops future firing; the disable event is part of the log, so the behavior remains auditable but no longer reacts.
A small but consequential discipline: sandbox and promoted execution share the same callable interface. The behavior sees behavior(event, graph, ctx), where graph is a read-only view and ctx is an emit-only context — the same constrained surface in validation and in deployment. There's no broader interface waiting in production. This eliminates a common class of failure where code passes a narrow mock test and then reaches for something wider at runtime.
Results: containment, not capability
The evaluation answers a specific question: does the lifecycle separate authorship from authority in practice? It does not measure whether the agent gets better at downstream tasks. That's a different question, addressed elsewhere; this work is about the boundary.
We ran three settings. A deterministic A/B/C baseline verified the authority progression: no code authoring (no behavior), draft-creation-without-promotion (validated but inert, never fires), full lifecycle (promoted behavior fires on matching events, stays silent on non-matching events, stops firing after disable). The important result is the middle row: validated drafts that haven't been promoted don't fire. Draft existence and behavior authority are separate states, and that separation is observable.
An adversarial corpus of 29 hand-authored cases — direct mutation attempts, forbidden imports, semantic-diff misfires, benign controls — tested whether the lifecycle rejects the failure classes it's designed to catch. All 29 matched expected outcomes: zero unexpected passes, zero unexpected failures, zero live graph violations.
The substantive measurement is the live LLM matrix: gpt-4o-mini authoring code for 23 mechanically checkable behavior goals, three trials each, 69 attempts total. The funnel was:
| Stage | Passed | Failed |
|---|---|---|
| Parse | 69 / 69 | 0 |
| Static analysis | 65 / 69 | 4 |
| Sandbox execution | 63 / 69 | 2 |
| Semantic diff | 60 / 69 | 3 |
| Promotion | 60 / 60 eligible | 0 |
| Matching-event fire | 60 / 60 promoted | 0 |
| Nonmatching silence | 60 / 60 promoted | 0 |
| Disable | 60 / 60 promoted | 0 |
Sixty of 69 attempts completed the full lifecycle. The 9 failures — 4 static, 2 sandbox, 3 semantic diff — all occurred before the authority boundary. No rejected draft ever became live behavior.
A sandbox can show that code ran. It cannot show that the graph now means the right thing.
The semantic-diff number is the one worth pausing on. 63 drafts passed sandbox execution; only 60 passed semantic diff. That means three drafts were syntactically clean and executable but produced the wrong graph effect. A sandbox-only promotion policy would have made them eligible for authority transfer. Static analysis asks whether the source is structurally allowed; sandbox execution asks whether the code runs under a constrained interface; semantic diff asks whether the graph effect means what the goal required. Those are different questions. The 63→60 gap is the entire empirical case for the third gate.
Of the 23 goals, 21 passed all three trials. The two informative zero-success goals are the ones that name the gates' purposes: url_extract_1 (failed sandbox and static analysis, as described above) and rel_summary_source (failed semantic diff all three times — code that ran but didn't produce the expected relation).
What the lifecycle does and does not do
The honest scope of these results is narrower than the language around code-generation safety usually carries.
What the lifecycle does: It separates authorship from authority structurally. A model authors source; the runtime decides whether to grant authority based on gated evidence. Failed drafts are caught at observable gates with recorded reasons, and the live graph is never mutated during validation. Promoted behaviors run through the same constrained interface used during sandboxing — there is no broader runtime surface waiting on the other side of promotion. The event-sourced substrate makes draft existence, validation results, promotion, and disable all queryable history: forensic questions about how a generated behavior became active have answers.
What it does not do. It does not prove arbitrary Python sandbox security — the static checks are pattern-based and the execution environment is not capability-secure in the strong sense required for hostile code. It does not generalize to arbitrary models or prompts — the matrix used one model (gpt-4o-mini) and one prompt family, and failures may distribute differently elsewhere. It does not address the semantic correctness of validators — a validator with an incomplete specification can be satisfied by an undesirable behavior. It does not study long-horizon interactions among many promoted behaviors, where cascades, conflicts, and drift become possible. And it does not erase past effects: disable stops future firing, but events the behavior already emitted into the log remain. Remediation, for a promoted behavior that turns out to be wrong, is really two operations — revocation (the disable event) and compensation (undoing the past graph effects), and this work addresses only the first.
There's also a candid implementation note. BehaviorDrafts runs on an ActiveGraph-backed adapter, not pure native ActiveGraph end-to-end. The adapter uses native primitives where they exist — graph, runtime, event, fork, diff — and adds a documented layer for lifecycle-specific operations like dynamic behavior registration, disable metadata, and diff normalization. That layer is also a finding. The fact that those operations currently live in the adapter rather than the substrate is evidence about where a native event-sourced runtime would need to grow to support authored-behavior authority end-to-end. Whether they should become first-class ActiveGraph primitives is an open question this work surfaces rather than settles.
Where this sits
BehaviorDrafts is one move in a fast-moving design space. Four neighborhoods are worth naming, because the contribution is sharper against them than alone.
Tool use and tool creation. Toolformer (Schick et al., 2023) trained models to decide when to call external APIs — tools as external capability the model invokes. More recent work moves toward agents that create tools: LATM (Cai et al., 2023) uses one model to generate reusable tools for another, treating tool-making as a functional cache. ToolMaker (Wölflein et al., 2025, ACL 2025) transforms papers-with-code repositories into LLM-compatible tools through dependency setup, wrapper generation, and self-correction. These systems establish that generated tools can be useful. BehaviorDrafts asks a different question: not whether a generated artifact is useful, but when it should be granted authority to affect future runtime state. Useful and authorized are not the same property.
Code as action and persistent skills. A parallel line treats executable code itself as the action representation. CodeAct (Wang et al., 2024) consolidates LLM agent actions into executable Python — code that can compose tools, control flow, and revise prior actions. Voyager (Wang et al., 2023) accumulates persistent code skills for open-ended exploration. Memento-Skills (Zhou et al., 2026) and CoEvoSkills (Zhang et al., 2026) build evolving skill libraries through reflective learning and co-evolutionary verification. These systems are complementary, not competing: code can be an effective action representation, and persistent skills can improve capability. BehaviorDrafts focuses on what happens after — once code is stored, selected, or bound to events, it has joined the agent's future operating surface, and the question shifts from did the code work to what evidence must exist before this artifact becomes live behavior.
Self-modifying and self-improving agents. Several systems widen the action space toward source-level self-modification. The Darwin Gödel Machine (Zhang et al., 2025) iteratively modifies its own codebase and validates changes empirically. SICA (Robeyns et al., 2025) demonstrates an LLM coding agent that edits its own implementation for benchmark gains. Concurrent work, MOSS (Cai et al., 2026), goes further — rewriting an agent's harness at the source level, verifying candidates against replayed production failures in trial workers, and promoting through a user-consented container swap. These systems operate at the high-expressivity end and demonstrate that capability gains from self-modification are real. BehaviorDrafts occupies a complementary point: it does not let the agent rewrite arbitrary runtime code. It defines a smaller authority unit — one generated behavior, represented as inert state, validated through gates, promoted under scoped trigger, and disableable through a logged event. The contribution is governance, not capability. The more practical source-level self-evolution becomes, the more the authorization gap matters.
Security, excessive agency, and self-evolving-agent risk. A separate literature studies how things go wrong: Misevolution (Shao et al., 2025) catalogues emergent risks when agents evolve through memory, tools, workflows, or model changes. Prompt Flow Integrity (Kim et al., 2025) addresses privilege escalation in LLM agents via least-privilege and untrusted-data validation. Recent work on tool-enabled agents (Goel, 2026, IEEE COMPSAC) highlights risks from privileged execution environments and ambient authority. OWASP's LLM Top 10 names excessive agency as a primary risk category. BehaviorDrafts does not solve arbitrary-Python sandbox security or malicious-model robustness — both are explicitly out of scope. Its narrower complementary contribution is structural: generated behavior does not inherit ambient authority merely by being generated. Authorship and authority are separate events, and the lifecycle makes that separation a property of the substrate, not of the policy layer.
The companion work, selfgraph, studies the same lifecycle one tier below — bounded graph-native self-change without authored code. BehaviorDrafts widens the action space to authored behavior source while preserving the same fork-diff-promotion boundary. The two posts together describe a graduated authority discipline: low-expressivity self-change first, authored code only after the lifecycle is validated.
Why this matters
LLM agents are moving from calling tools toward creating, storing, revising, and deploying executable artifacts. The trajectory is clear: source-level self-modification, persistent skill libraries, agents editing their own code paths. Each step makes the authorization gap more consequential, not less. If generated code is going to affect runtime behavior, the question of when it becomes authorized is going to need a real answer in every serious system.
The authorization gap exists whether or not it's named. Direct-install architectures answer it implicitly — authority is granted as a side effect of generation, possibly with tests. That answer works when generation is rare, supervised, and the runtime is mostly static. It scales badly when generation becomes ordinary, frequent, and the runtime is dynamic. A self-extending agent that grants authority on generation will accumulate behaviors it cannot account for. A self-extending agent that records which artifacts received authority, when, under what evidence, with what scope, and how to disable them can be inspected, audited, and repaired. The substrate decides which of those is possible.
BehaviorDrafts is a constrained demonstration of the second posture. The empirical result — 60 of 69 attempts completing the full lifecycle, all 9 failures caught before authority transfer — is bounded. The semantic-diff gate catching three executable-but-wrong drafts is a small number with a large argument behind it. The reusable contribution is the lifecycle pattern: let agents author code, but do not let authored code act until authority is explicitly earned, logged, scoped, and reversible.
That is code without authority.
Code and reproduction artifacts (Apache-2.0): github.com/yoheinakajima/activegraph-behaviordrafts (v1.0.0), built on ActiveGraph (github.com/yoheinakajima/activegraph). Install with pip install -r requirements.txt and run python scripts/run_all.py; default execution is deterministic and requires no API key. The live LLM matrix (gpt-4o-mini) runs under the opt-in --llm flag.
← back to blog