What Semantic Memory Forgets: ActiveGraph on LongMemEval-S
Debugging ActiveGraph on LongMemEval-S: LLM extraction moved the semantic-memory pack from 60.6% to 83.4%, role-aware assistant retention fixed a 75.0% → 98.2% assistant-memory failure class, and the remaining errors showed why semantic memory should compile back to source evidence.
- research
- benchmark
- LongMemEval-S
We evaluated ActiveGraph’s semantic-memory pack on all 500 cleaned LongMemEval-S questions. The first result was unsurprising: replacing deterministic observation memories with LLM-extracted semantic memories improved accuracy inside the current semantic-pack harness from 60.6% to 83.4%.
The second result was more interesting: the semantic projection was opinionated about what counted as memory.
It remembered the user and forgot the assistant.
Questions that asked what the assistant had previously said or produced fell from 96.4% under the deterministic path to 75.0% under LLM extraction. Flat and agentic retrieval failed on the same 14 questions, and every failure was a retrieval miss. The facts were not hard to retrieve. They had not been stored.
A role-aware ingest fix that writes assistant-authored memories as assistant facts recovered all 14 coverage failures and raised single-session-assistant to 98.2%. Net effect: +13 of 56, p = 0.0010. Overall accuracy rose to 84.8%.
But that fix also made the deeper lesson clearer: semantic memory is a projection over the log, and projections are lossy. After role-aware retention, the remaining bottleneck was no longer mostly retrieval. Most answerable failures happened with gold-turn provenance already in context, especially on temporal arithmetic, cross-session aggregation, supersession, preference grounding, and a smaller but real class of span-loss/fidelity errors.
This is the useful result:
Long-term memory is not just retrieval. It is representation, retrieval, provenance, and evidence use.
ActiveGraph matters here not because it magically solves memory, but because it makes memory failures inspectable. The system could show what was written, what was missing, what was retrieved, what was compressed away, and what the reader failed to use.
Key results
| Metric | Result |
|---|---|
| Deterministic pack baseline (flat retrieval) | 60.6% |
| LLM extraction, flat retrieval | 83.4% |
| LLM extraction, agentic retrieval | 84.0% |
| LLM extraction + assistant retention, flat | 84.8% |
single-session-assistant, LLM extraction only | 75.0% |
single-session-assistant, with assistant retention | 98.2% |
Targeted net effect on single-session-assistant | +13 of 56, p = 0.0010 |
TL;DR — LLM-extracted semantic memories improved recall, but the first projection dropped assistant-authored facts. Role-aware assistant retention recovered the targeted failure class, while the remaining errors shifted from retrieval to evidence use and fidelity. The next architecture should retrieve semantic claims, then compile back to raw source spans.
Series context: substrate → projection → hybrid
This is the second post in the ActiveGraph LongMemEval-S series. The first, Evidence Compilation Before Semantic Memory, reached 85.6% QA accuracy at 2,462 mean context tokens using a deterministic event-sourced substrate — no LLM-generated memory at ingest. This post tests the next layer: what happens when ActiveGraph starts writing LLM-extracted semantic memories on top of that log.
The arc is:
Post 1: The log can retrieve.
Post 2: Semantic projections are powerful but lossy; ActiveGraph makes the loss auditable.
Post 3: The right memory architecture compiles semantic projections back into source evidence.
The 85.6% (post 1) and 84.8% (post 2) numbers are different systems with different judges and context regimes, not leaderboard entries. The point here is narrower:
Inside the semantic-memory pack, LLM extraction improves recall, exposes representational failure, and shifts the remaining bottleneck toward evidence use and fidelity.
What ActiveGraph is doing here
ActiveGraph is not primarily a memory product. It is an event-sourced graph runtime for AI agents.
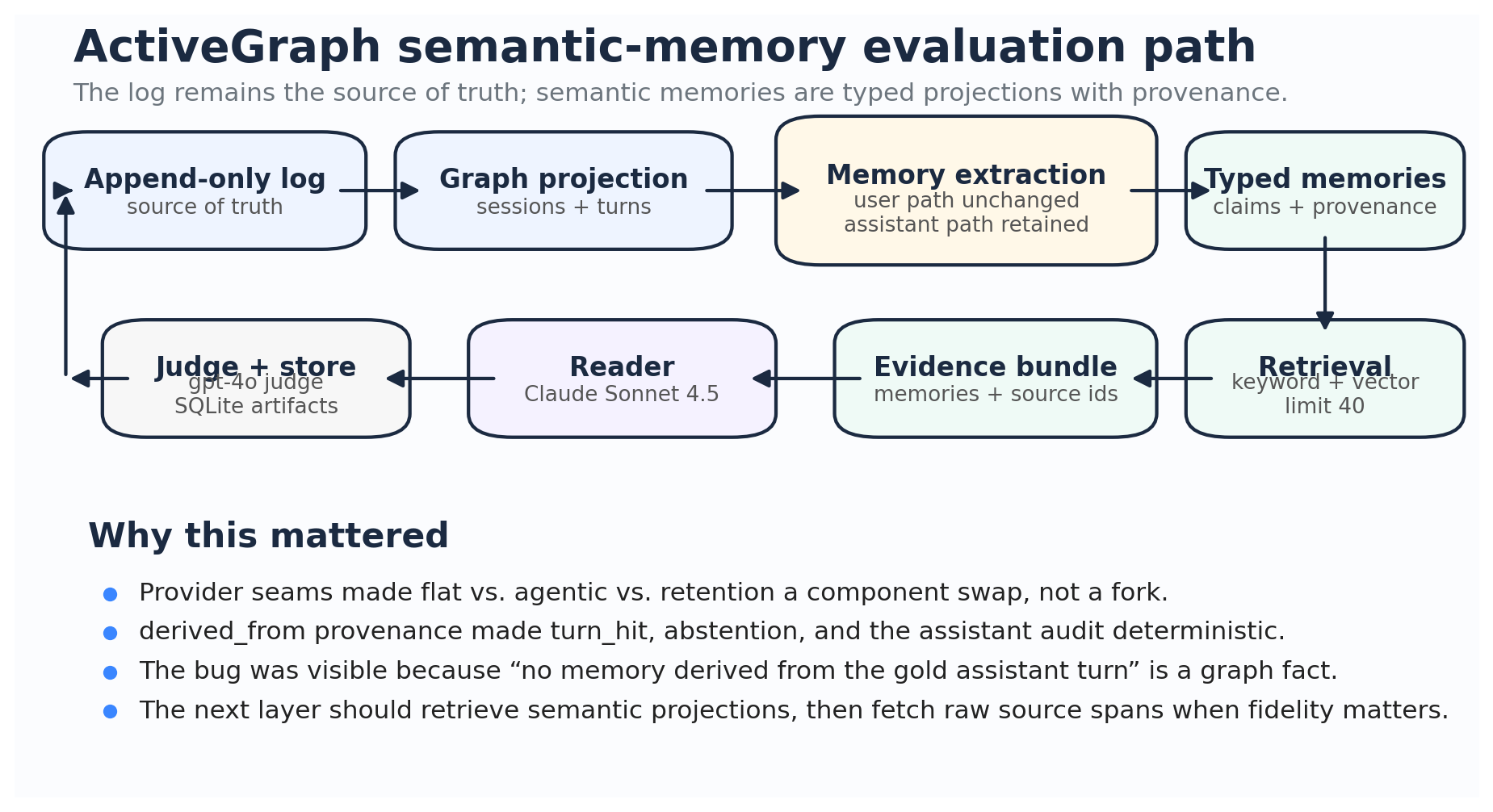
The short version:
append-only event log
→ deterministic graph projection
→ reactive behaviors
→ new events
For memory, that means conversations are not just dumped into a vector store. They become replayable state. Memory claims, source turns, retrieval plans, retrieval results, and answers can all be represented as graph objects with provenance edges.
That matters because memory failures become inspectable.
A typical RAG failure might say:
the answer was wrong
An ActiveGraph memory failure can ask:
Was the source turn in the log?
Was a memory derived from it?
What role was assigned to that memory?
Was it consolidated or discarded?
Was it retrieved?
Was its source provenance present?
Did the answer-bearing span survive compression?
Did the reader use the evidence?
That is the architecture this benchmark is dogfooding. LongMemEval-S is narrow, but useful: it creates a concrete pressure test for whether memory projections over an agent log actually help, what they forget, and whether those failures can be traced.
Benchmark and setup
LongMemEval-S is a long-term chat memory benchmark. Each instance contains a multi-session user-assistant history and a question whose answer depends on one or more prior turns. It targets information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention.
We ran four configurations over the same 500 cleaned LongMemEval-S questions:
| Short name | Run artifact | Extraction | Retrieval | Assistant retention | Accuracy |
|---|---|---|---|---|---|
| Deterministic pack baseline | full-s-sonnet | deterministic | flat | — | 60.6% |
| Flat LLM | task18-flat-500 | LLM | flat | off | 83.4% |
| Agentic LLM | task18-agentic-500 | LLM | agentic | off | 84.0% |
| Retain | task19-retain-500 | LLM | flat | on | 84.8% |
Fixed across the main LLM-extraction runs:
- Reader: Claude Sonnet 4.5, requested as
claude-sonnet-4-5, resolved asclaude-sonnet-4-5-20250929, temperature 0. - Judge:
gpt-4o-2024-08-06, temperature 0. - Retrieval: keyword + vector blend, primary limit 40, no reranking, no HyDE, no query expansion.
- Dataset: cleaned LongMemEval-S, n = 500, seed 42.
The deterministic baseline used a different judge snapshot, gpt-4o-2024-11-20. That means deterministic-vs-LLM comparisons are not judge-clean. The flat-vs-agentic and flat-vs-retain comparisons are the clean causal comparisons.
The retention A/B is unusually clean. User-turn extraction is byte-identical between task18-flat-500 and task19-retain-500: the same cache key and prompt produce the same cached user memories. Only assistant turns route through the new assistant-retention path. That was verified by a parity test, test_user_path_identical_regardless_of_retain_flag.
Main result: semantic extraction improved recall, then exposed evidence use
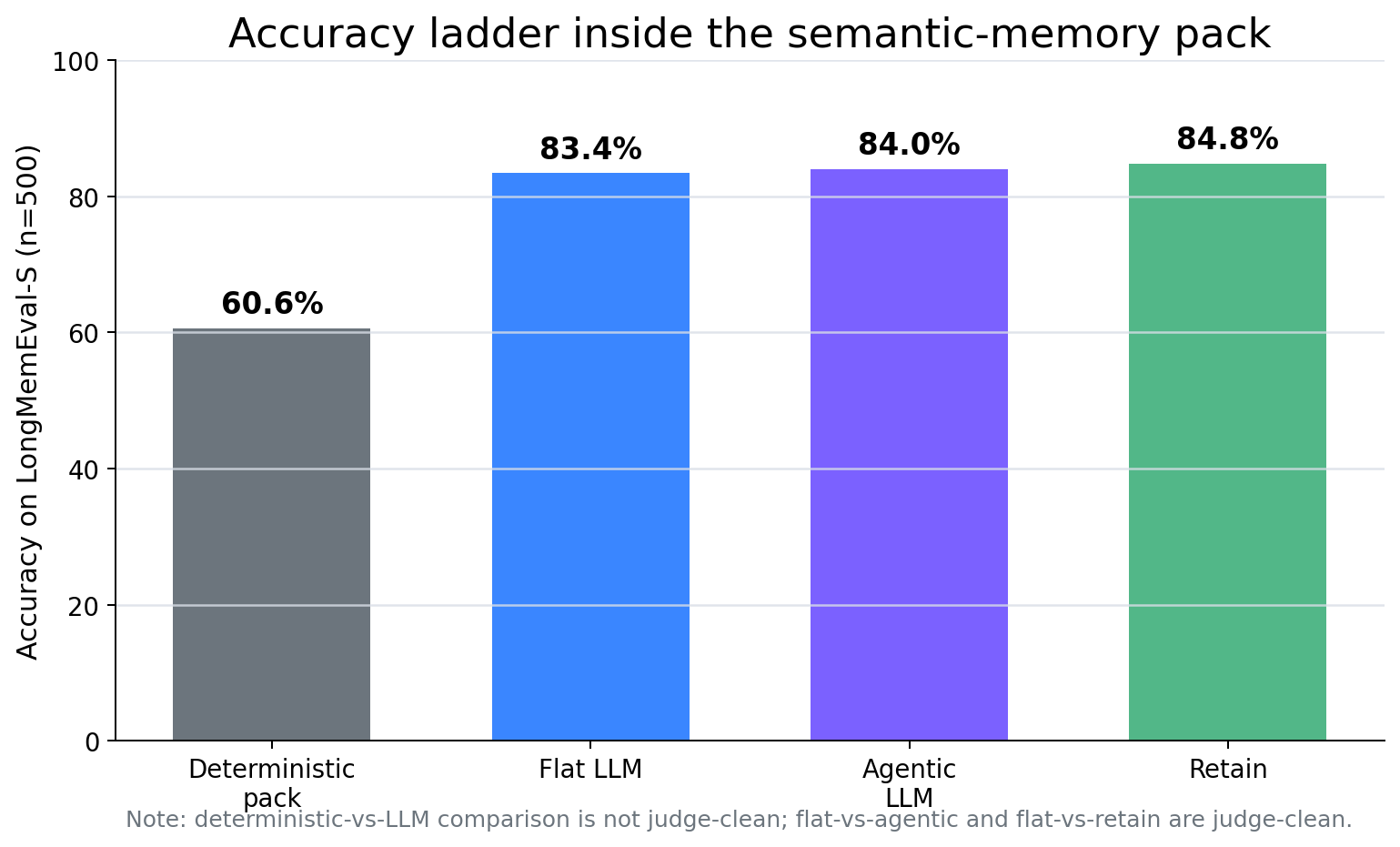
Within the current semantic-pack harness, LLM extraction produced the largest observed gain: 60.6% → 83.4% under flat retrieval.
Because the deterministic baseline used a different judge snapshot, the exact p-value for deterministic-vs-LLM should not be overstated. The qualitative effect is large, but the clean paired causal comparisons are flat-vs-agentic and flat-vs-retain.
Agentic retrieval did not produce a statistically detectable gain over flat retrieval: 84.0% vs. 83.4%, net +3 of 500, p = 0.72. A more elaborate retrieval loop was not the next useful default lever in this harness.
Assistant retention added only +1.4 points overall, from 83.4% to 84.8%, and that aggregate delta is not significant. But aggregate accuracy is the wrong unit of analysis for this fix. The targeted type, single-session-assistant, is only 56 of 500 questions. On that type, retention moved 75.0% → 98.2%.
| Comparison | b | c | Net | p_exact | Reading |
|---|---|---|---|---|---|
| Deterministic vs. flat LLM | 27 | 141 | +114 | <1e-15 | Large observed gain, but judge differs |
| Flat LLM vs. agentic LLM | 14 | 17 | +3 | 0.72 | No detected gain |
| Flat LLM vs. retain, overall | 29 | 36 | +7 | 0.457 | Overall delta includes zero |
| Flat LLM vs. retain, assistant type only | 1 | 14 | +13 | 0.0010 | Targeted gain |
A paired bootstrap says the same thing. The overall retain-minus-flat delta is +1.4 points with a 95% CI of [-1.8, +4.6], while the single-session-assistant delta is +23.2 points with a 95% CI of [+10.7, +35.7]. The assistant-type gain also survives Holm and Bonferroni correction across the six question types.
The bottleneck flip
The most important table in the run is not the accuracy table. It is the error decomposition.
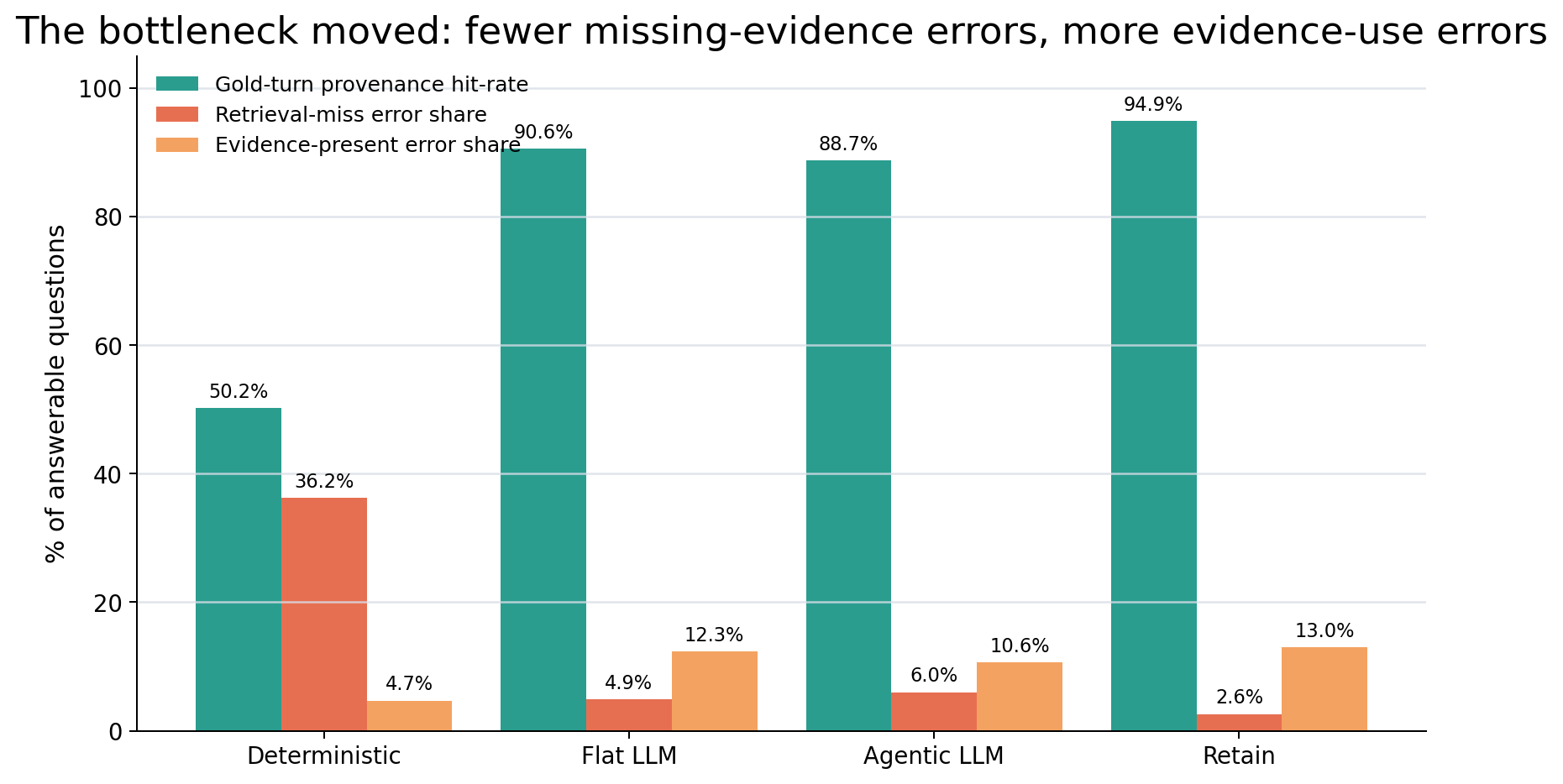
For the 470 answerable questions, we check whether all labeled gold turns reached the reader context through retrieved memories’ provenance. I call that turn_hit:
turn_hit = gold_turns ⊆ ctx_turns
where ctx_turns are source-turn IDs recovered from retrieved memory provenance.
This is a provenance-coverage metric. It is not raw-turn retrieval, and it does not prove the exact answer span survived semantic compression. That distinction matters.
| Run | Gold-turn provenance hit-rate | Accuracy when hit=1 | Accuracy when hit=0 | Evidence-present error share | Retrieval-miss error share |
|---|---|---|---|---|---|
| Deterministic | 50.2% | 90.7% | 27.4% | 4.7% | 36.2% |
| Flat LLM | 90.6% | 86.4% | 47.7% | 12.3% | 4.9% |
| Agentic LLM | 88.7% | 88.0% | 47.2% | 10.6% | 6.0% |
| Retain | 94.9% | 86.3% | 50.0% | 13.0% | 2.6% |
Definitions:
- Retrieval-miss error share: answerable questions where gold-turn provenance is missing and the answer is wrong.
- Evidence-present error share: answerable questions where gold-turn provenance is present and the answer is wrong.
The deterministic pack baseline is retrieval-limited. It retrieves all labeled gold turns on only 50.2% of answerable questions, and 36.2% of answerable questions fail because the evidence is missing.
LLM extraction changes the shape of the problem. Flat LLM extraction pushes hit-rate to 90.6% and drops retrieval-miss error share to 4.9%. Retention pushes hit-rate to 94.9% and retrieval-miss error share to 2.6%.
So retrieval misses are no longer the dominant measured failure mode. The remaining errors are mostly evidence-use failures: reader reasoning, context ordering, stale-fact reconciliation, and, in a smaller number of cases, semantic compression that lost the exact answer span.
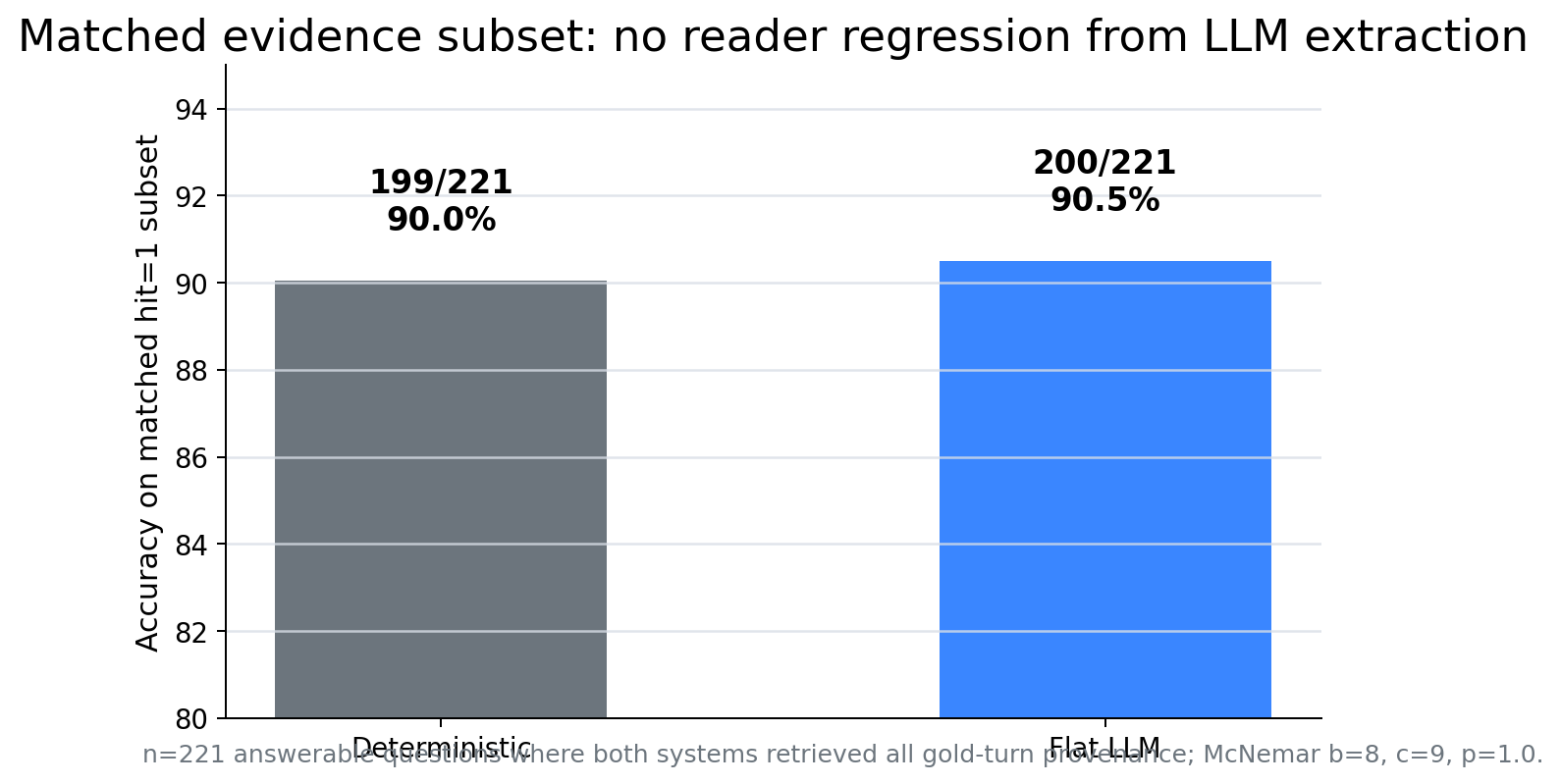
A matched-hit subset check closes one important loophole. Among answerable questions where both deterministic and flat-LLM systems have turn_hit=1, deterministic scores 199/221 and flat LLM scores 200/221, with McNemar p = 1.0. So the lower accuracy | hit=1 under LLM extraction is a selection effect, not evidence that LLM extraction degraded reader accuracy. The deterministic path retrieves evidence mostly for easier questions; LLM extraction retrieves evidence for harder questions too.
The projection bug: semantic memory forgot what the assistant said
Here is the exact moment the run became interesting.
single-session-assistant asks questions about the assistant’s own prior outputs: a chess move it made, a list it produced, a recommendation it gave, a number it calculated. Under the deterministic path, this type scored 96.4%. Under LLM extraction, it fell to 75.0%.
Flat retrieval and agentic retrieval both scored 42/56. More importantly, they failed on the identical 14 questions. Every one of those 14 had turn_hit=0: no memory derived from the gold assistant turn reached the reader.
That is the fingerprint of an ingest defect. Two retrieval algorithms cannot recover facts that were never written. The extractor was designed to preserve durable facts about the user. That is a reasonable product instinct, but LongMemEval-S also asks what the assistant said. So the memory writer quietly dropped the assistant.
This is not just a bug. It is a projection failure.
The semantic projection encoded an assumption:
durable memory = facts about the user
LongMemEval-S exposed the missing category:
durable memory can also include prior assistant outputs
Example failure pattern:
| Source event | Retention off | Retention on |
|---|---|---|
| Assistant recommends language apps, including Memrise | No durable assistant-authored fact retrievable for “what app did you recommend?” | “The assistant recommended the language learning apps Duolingo, Rosetta Stone, Babbel, Memrise, and Lingodeer …” |
| Assistant makes a chess move | No retrievable memory of the move | “The assistant made the move 28. Kg3 in a chess game.” |
| Assistant provides a 100-item parameter list | List not retained in answer-bearing form | “The assistant provided a list of 100 prompt parameters …” |
The fix was not to broaden retrieval. It was to change what gets written.
The role-aware retention fix
The fix adds a role-aware assistant-turn extraction path. When retain_assistant_facts is on, assistant turns can produce assistant-authored memories phrased as “The assistant …” facts. User-turn extraction stays byte-identical.
Result: all 14 flat-LLM assistant coverage failures are recovered.
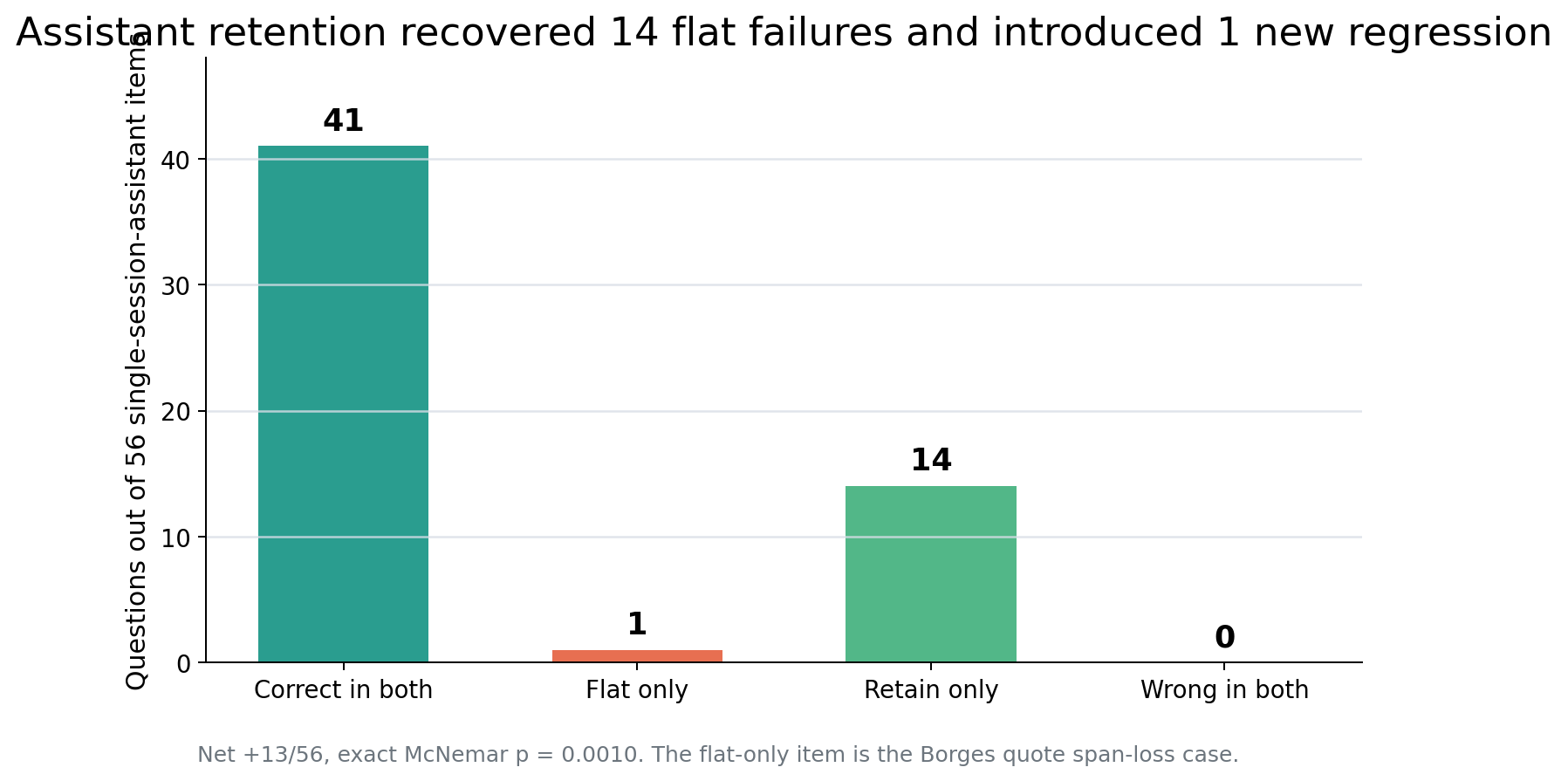
single-session-assistant outcome | Count |
|---|---|
| Correct in both flat and retain | 41 |
| Correct only in flat | 1 |
| Correct only in retain | 14 |
| Wrong in both | 0 |
That table is the cleanest way to state the result. Retention recovered 14 failures from flat LLM extraction, but it also introduced one new assistant-type regression. Net: +13.
The 14 recovered answers include 28. Kg3, Memrise, Patagonia and Southwest Airlines, @jessica_poole_jewellery, the 27th item in a 100-parameter list, and a tourism-board phone number. In every recovered case, turn_hit flips 0 → 1: under flat LLM extraction, the gold assistant turn produced no retrievable answer-bearing memory; under retention, a “The assistant …” memory derived from that exact turn appears in context.
This is why the fix is convincing. It is not a generic benchmark bump. It is a causal story with provenance.
There is also an operational surprise: total extracted memories fall from a mean of 779.9 to 718.5 per question. That sounds backwards until you inspect the paths. With retention off, assistant turns are still processed by a liberal user-centric prompt, which emits many misattributed or non-recallable memories. With retention on, assistant turns route to a more selective assistant prompt.
The system writes fewer memories, but more of them are answer-bearing.
That is the benefit of typed representation: not “store more,” but “store the right thing under the right type.”
The Borges regression: coverage was fixed, fidelity was not
The one flat-correct/retain-wrong assistant question is 58470ed2, the Borges quote.
This matters because it is easy to describe the result incorrectly. Retention did not leave one of the original 14 assistant coverage failures unresolved. It recovered all 14. But it introduced one new assistant-type regression.
The question asks for a verbatim quote from the assistant’s prior discussion of The Library of Babel:
The Library is a sphere whose exact center is any one of its hexagons and whose circumference is inaccessible.
Under flat LLM extraction, the relevant verbatim quote terms were present in context, and the reader answered correctly.
Under retain, the assistant extractor stored a memory about Borges and the Library, but paraphrased the source turn as an indefinite number of hexagonal galleries and dropped the exact “sphere / center / circumference” sentence. The topic survived. The quote did not.
That is not the same failure as the original 14. It is a fidelity failure from lossy compression.
This is the architectural lesson:
Semantic memory should compile from the log, not replace it.
The log preserves exact source spans. Semantic extraction creates compact, retrievable projections. When a question asks for a quote, list item, code snippet, calculation, recommendation, or assistant-generated artifact, the system should retrieve the semantic memory and then follow provenance back to the raw source span.
This case is small, but it points directly to the next experiment: preserve verbatim anchors for assistant turns that contain quotes, lists, calculations, code, or generated artifacts.
What still fails: evidence use, not mostly retrieval
With assistant coverage fixed, the remaining errors cluster around evidence use.
I am deliberately saying evidence use, not only reasoning, because turn_hit=1 means gold-turn provenance reached context. It does not prove the answer span survived compression, that the evidence was ordered well, or that conflicting facts were clearly marked. Manual inspection still suggests most are reader-side reasoning or evidence-use failures, but the metric itself should be read as provenance coverage.
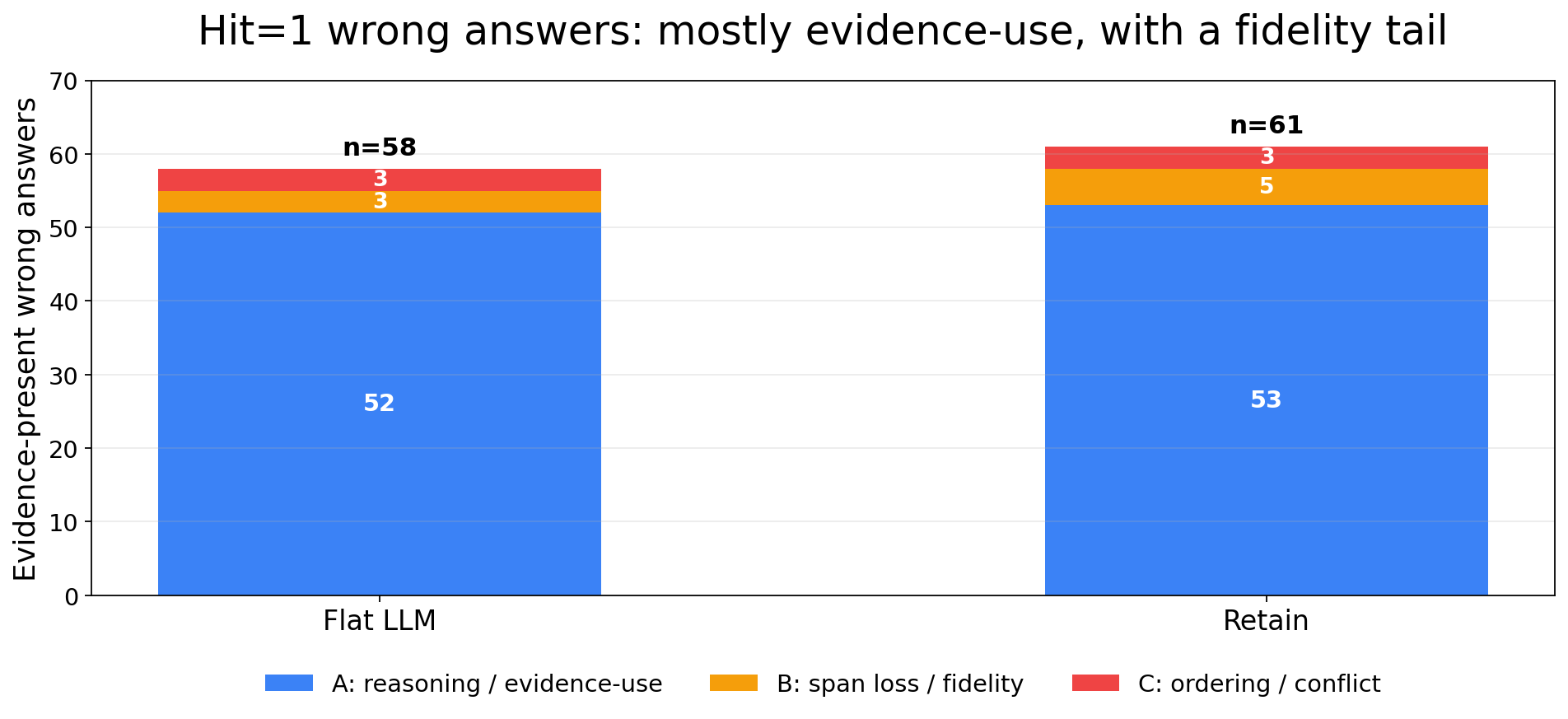
The no-rerun cleanup pass triaged evidence-present wrong answers:
| Run | Evidence-present wrong | Reasoning / evidence-use | Span loss | Ordering / conflict | Unclear |
|---|---|---|---|---|---|
| Flat LLM | 58 | 52 | 3 | 3 | 0 |
| Retain | 61 | 53 | 5 | 3 | 0 |
The main clusters:
| Failure mode | Shape of the error |
|---|---|
| Temporal arithmetic | Dates are present, but interval math is wrong |
| Cross-session aggregation | Items/events are present, but counting or binding fails |
| Supersession / current-state selection | Old and new facts are present, but the stale fact is chosen |
| Preference grounding | Relevant user behavior is present, but the answer is generic |
| Span loss | A memory derived from the right turn is present, but the answer-bearing span was compressed away |
| Ordering / conflict | Evidence is present but hard to use because context contains competing or poorly ordered material |
Examples:
- Temporal arithmetic: the evidence contains Jan 19 and Apr 10, but the reader answers “12 weeks” where the gold answer is 15.
- Aggregation: the reader lists three art events when the gold answer requires four.
- Supersession: both “under your bed” and the newer “shoe rack” are retrieved, but the reader picks the stale location.
- Preference grounding: the user previously bought a power bank, but the answer gives generic phone-battery advice instead of grounding in that fact.
- Span loss: the memory points to the right source turn, but the exact answer text was paraphrased away.
These are exactly the kinds of failures that make long-term memory hard. A better retriever helps until the evidence is present. After that, the system needs date normalization, aggregation, recency selection, contradiction handling, and answer-span fidelity.
Why a generic reasoning scaffold did not help
Given the bottleneck flip, the next obvious experiment was a read-time reasoning scaffold.
We added a non-parity reader mode that asks the model to produce structured visible evidence notes, identify the question type, perform date/aggregation/current-state computation, and emit a concise ANSWER: field. This was not a hidden “think step by step” prompt. It was a visible evidence compiler.
It regressed the 50-question validation slice: 94.0% → 88.0%.
It fixed exactly one question, a knowledge-update case, and broke four: one multi-session, one temporal-reasoning, and two preference questions. Mean completion length grew from 97 to 449 tokens, and the answer parser remained reliable. The regression looks like overthinking, not a formatting failure.
There is one caveat: the scaffold run pins the -20250929 Sonnet snapshot, while the parity manifest records the alias. The artifacts cannot prove the same snapshot, although only one Sonnet 4.5 snapshot was known on the proxy. This should therefore be treated as a useful negative result, not a final claim about all reasoning scaffolds.
The lesson is narrow: generic scaffolding is not a free win. Future reader-side work should be more targeted:
- deterministic date normalization and interval computation;
- explicit event extraction, deduplication, and counting;
- recency/supersession selection before the reader sees conflicting facts;
- preference grounding that forces answers to use known user behavior when relevant;
- provenance-backed raw-span fallback for quotes, lists, code, and calculations.
Cost: retention costs context, not retrieval breadth
Assistant retention does not broaden retrieval. The primary retrieval limit remains 40. Median and p95 retrieved-set sizes are 40 in both flat and retain runs; a fallback occasionally adds a few items, but the distribution is effectively unchanged.
What grows is per-item length. Retained assistant memories preserve more lists, numbers, and generated artifacts.
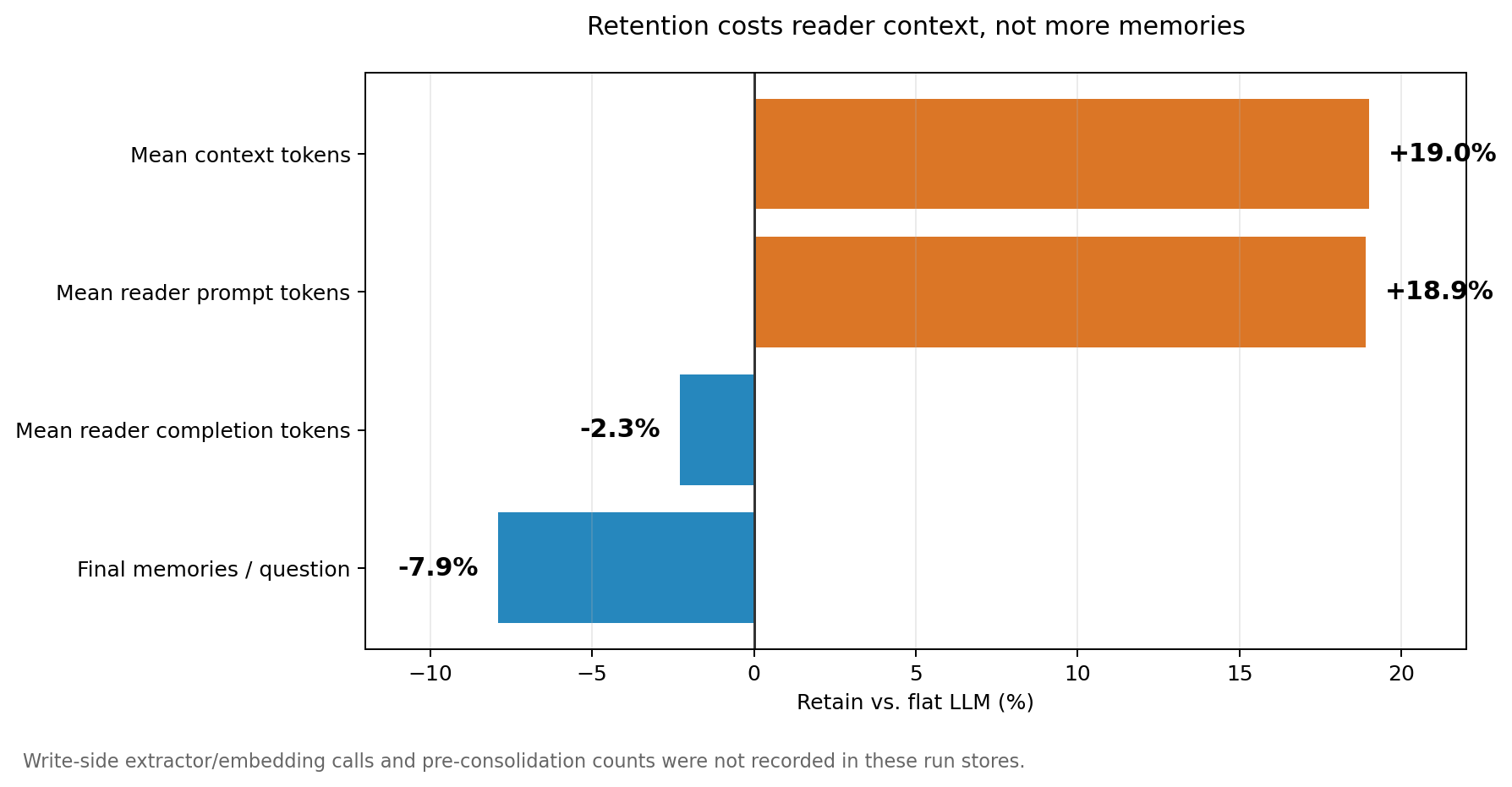
| Metric | Flat LLM | Retain | Change |
|---|---|---|---|
| Mean reader context | 8,042 tokens | 9,569 tokens | +19.0% |
| Median reader context | 7,896 tokens | 9,174 tokens | +16.2% |
| p95 reader context | 10,923 tokens | 14,027 tokens | +28.4% |
| Total reader prompt tokens | 4,486,191 | 5,332,961 | +846,770 |
| Total reader completion tokens | 48,115 | 47,010 | -1,105 |
| Mean extracted memories / question | 779.9 | 718.5 | -7.9% |
| Store size | 20.7 MB | 24.0 MB | +3.3 MB |
We do not publish a wall-clock comparison from these runs. Both were heavily cache-served, so runtime is cache-warmth-confounded.
Several write-side cost fields were not recorded: extractor call count, extractor input/output tokens, embedding calls/tokens, pre-consolidation memory count, and stage-level write latency. Future runs should write these into the store or manifest so semantic-memory cost can be measured end-to-end.
Why ActiveGraph made this failure useful
This section is not the main result, but it explains why the audit was possible.
ActiveGraph gives three affordances that mattered here.
1. Replayable state
Memory state is a projection over a deterministic event log. That made the clean retention A/B possible: user-turn extraction could be shown identical by construction, not only by statistics.
2. Provider seams
Extraction, embeddings, retrieval, and reranking are swappable providers inside the same pack. The four conditions are not forks of the system; they are the same runtime with one component changed.
3. First-class provenance
Claims link back to source observations. That is how turn_hit, session-hit, and the 14-question assistant audit could be computed deterministically without asking another LLM to explain what happened.
So the runtime story is not “ActiveGraph makes memory easy.” It is more specific:
ActiveGraph made the memory projection debuggable.
The writer forgot assistant-authored facts, and the provenance graph made that visible.
What this says for agent memory builders
This result is not specific to ActiveGraph.
If you are building long-term agent memory, you probably need role-aware schemas. A user preference, an assistant recommendation, a generated list, a calculation, a code snippet, and a superseded fact are different memory objects. Treating all of them as generic “facts about the user” will lose information. Treating all of them as raw transcript will lose abstraction.
A good memory system needs at least four layers:
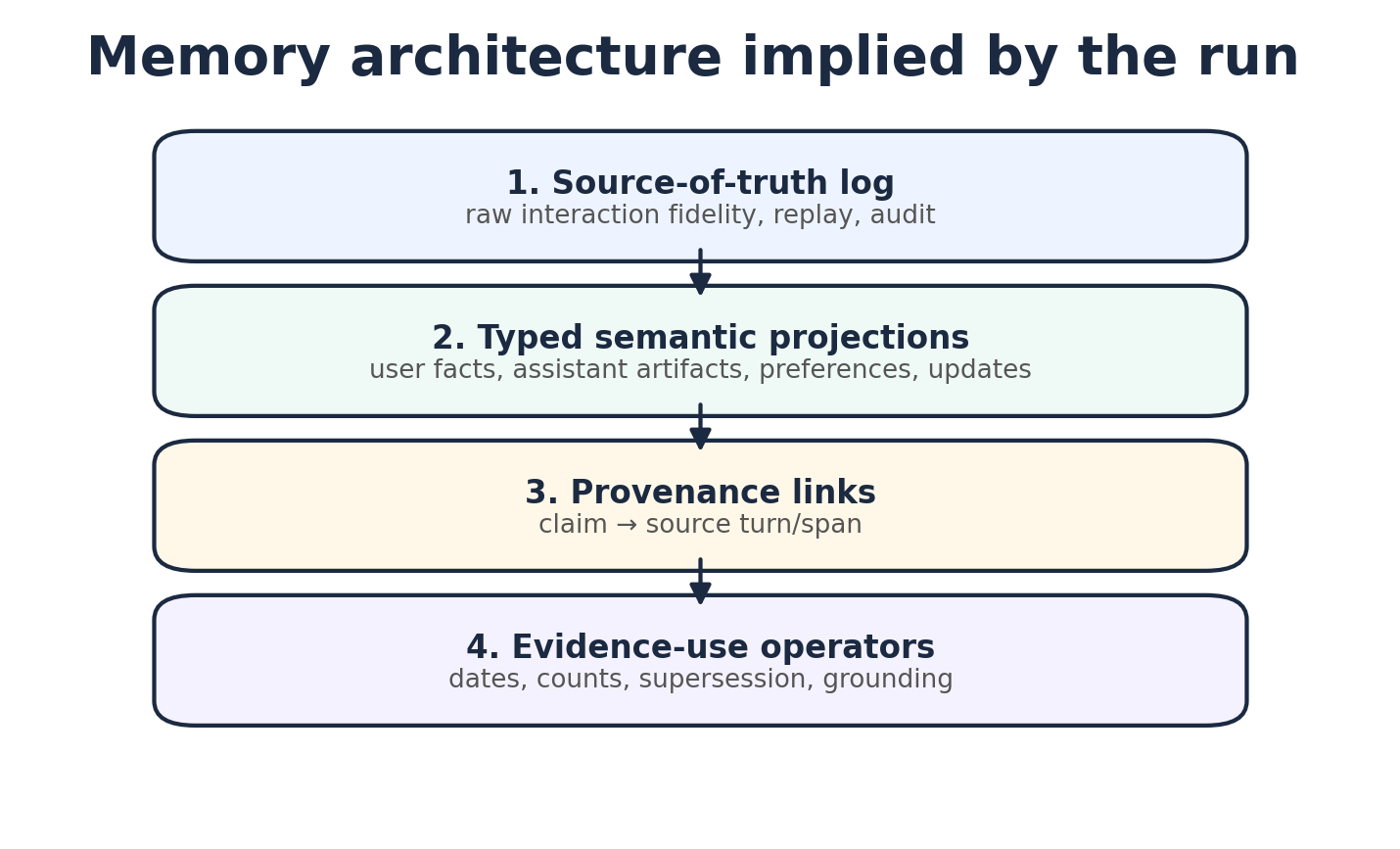
1. source-of-truth log
exact history, replay, audit, fidelity
2. typed semantic projections
user facts, assistant facts, preferences, artifacts, events, updates
3. provenance links
every projection points back to source turns or spans
4. evidence-use operators
dates, counts, supersession, grounding, span fallback
Semantic extraction is necessary, but not sufficient. It can improve recall and still encode the wrong idea of what is worth remembering.
The follow-up architecture should not choose between raw evidence and semantic memory. It should use both:
semantic facts = findability, abstraction, update semantics
raw source spans = fidelity, exact quotes, lists, code, calculations
The next experiment is therefore not “more agentic retrieval.” It is hybrid compilation:
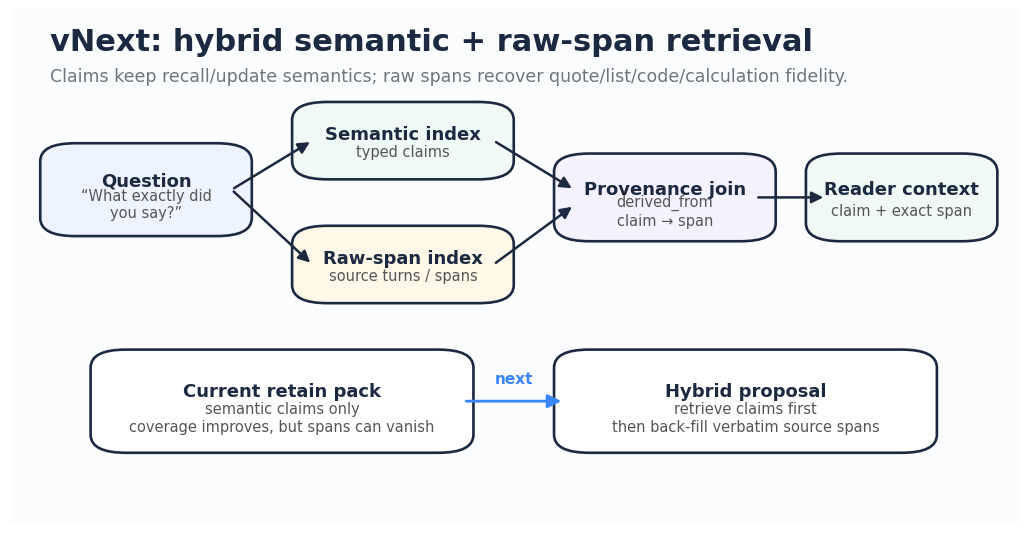
retrieve semantic claim
→ follow provenance to source turn/span
→ include both claim and source evidence when exactness matters
That is the bridge to the next post: Compile From the Log, Don’t Replace It.
What this post does not claim
This is a dogfooding report, not a leaderboard claim.
It does not claim:
- retained semantic memory beats the older deterministic ActiveGraph evidence compiler;
- graph topology is the isolated causal reason for any score;
- agentic retrieval is never useful;
- generic scaffolds never help;
- the assistant-retention gain will generalize at the same magnitude beyond LongMemEval-S;
- small per-type regressions are impossible.
The flat-vs-retain comparison is judge-clean and causal inside this harness. The deterministic-vs-LLM comparison is large but not judge-clean. The assistant-retention fix was motivated by inspecting LongMemEval-S failures and evaluated on the same benchmark, so the mechanism is clear but the exact gain may be benchmark-specific. A held-out memory benchmark or LongMemEval-V2-style setting is needed to estimate generalization.
The older deterministic evidence-compiler result remains an unresolved comparison. This post does not answer whether retained semantic memory beats that earlier substrate under matched judge, reader, retrieval path, and context budget. It answers a different question: what semantic projection changes inside the current pack, what it breaks, and where the bottleneck moves.
What I would measure next
There are three obvious next experiments.
1. Matched substrate-vs-semantic comparison
| Condition | Ingest / memory path | Context budget | Question answered |
|---|---|---|---|
| A | Earlier deterministic evidence compiler | ~2.5k | Reproduce the substrate lane |
| B | Retained semantic memory | ~2.5k | Does semantic memory help under compact budget? |
| C | Earlier deterministic evidence compiler | ~9.5k | Does the substrate catch up or degrade with more context? |
| D | Retained semantic memory | ~9.5k | Current final system, budget-matched |
This separates memory path from context budget.
2. Hybrid semantic + raw evidence compilation
The architecture suggested by this post is:
retrieve semantic memories
→ follow provenance back to raw source turns/spans
→ include raw spans for quotes, lists, code, calculations, and assistant artifacts
→ let the reader answer from both abstraction and evidence
This directly tests whether semantic abstraction and deterministic evidence fidelity are complementary.
3. Evidence-use operators
Once retrieval is strong, the next gains probably come from targeted operators rather than broader retrieval loops:
- date normalization;
- interval computation;
- event aggregation;
- supersession/current-state resolution;
- preference grounding;
- quote/list/code/calculation span anchoring.
These should probably be graph behaviors, not only prompt instructions.
Reproduction
Run artifacts:
| Run | Description | Overall accuracy |
|---|---|---|
runs/full-s-sonnet/ | deterministic + flat | 60.6% |
runs/task18-flat-500/ | LLM + flat, retention off | 83.4% |
runs/task18-agentic-500/ | LLM + agentic, retention off | 84.0% |
runs/task19-retain-500/ | LLM + flat, retention on | 84.8% |
Analysis commands:
cd longmemeval-harness
../.pythonlibs/bin/python -m analysis.significance \
--det full-s-sonnet \
--flat task18-flat-500 \
--agentic task18-agentic-500 \
--retain task19-retain-500
../.pythonlibs/bin/python -m analysis.failures \
--flat task18-flat-500 \
--retain task19-retain-500
Dataset sha256:
d6f21ea9d60a0d56f34a05b609c79c88a451d2ae03597821ea3d5a9678c3a442
Judge prompt path:
longmemeval_harness/judge.py
Judge prompt sha256:
506a8994de37e9fff6660a4d2a7c3a826f3e39028ca4fe1cfb4cdcba0acc0cee
Scaffold 50-question slice hash:
e293d7b2239da1e2ff2097ae44138e872cfa95e47a5400c0c9fed5c6dcf5a107
Extractor model:
gpt-4o-mini
The extractor model is recorded as an alias; the exact snapshot was not resolved in the original run. Future runs should record requested and resolved model identifiers for every external model call.
Each store.sqlite contains one row per question with retrieval result, assembled context, reader hypothesis, gold answer, judge decision, turn/session recall and hit, token counts, and latencies. Run configuration is recorded in each manifest.json.
References
- Di Wu et al., LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR 2025.
- Yohei Nakajima, Evidence Compilation Before Semantic Memory: ActiveGraph on LongMemEval-S, 2026.
- Yohei Nakajima, The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems, 2026.
- Nelson F. Liu et al., Lost in the Middle: How Language Models Use Long Contexts, TACL 2024.
- Cheng-Yu Hsieh et al., Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization, ACL Findings 2024.
- Jiaqi Wei et al., AlignRAG: An Adaptable Framework for Resolving Misalignments in Retrieval-Aware Reasoning of RAG, 2025.
- Deepthi Potluri et al., CARE-RAG: Clinical Assessment and Reasoning in Retrieval-Augmented Generation, 2025.
- Sourav Verma, Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey, 2024.
- Preston Rasmussen et al., Zep: A Temporal Knowledge Graph Architecture for Agent Memory, 2025.
- Prateek Chhikara et al., Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025.
← back to blog