Compile From the Log, Don't Replace It
Hybrid Semantic Memory on LongMemEval-S: Retrieval Significance, Reader Bottlenecks, and the Case for Provenance-Backed Facts
- research
- benchmark
- LongMemEval-S
- semantic-memory
- evaluation
- activegraph
Hybrid Semantic Memory on LongMemEval-S: Retrieval Significance, Reader Bottlenecks, and the Case for Provenance-Backed Facts
Yohei Nakajima — May 2026
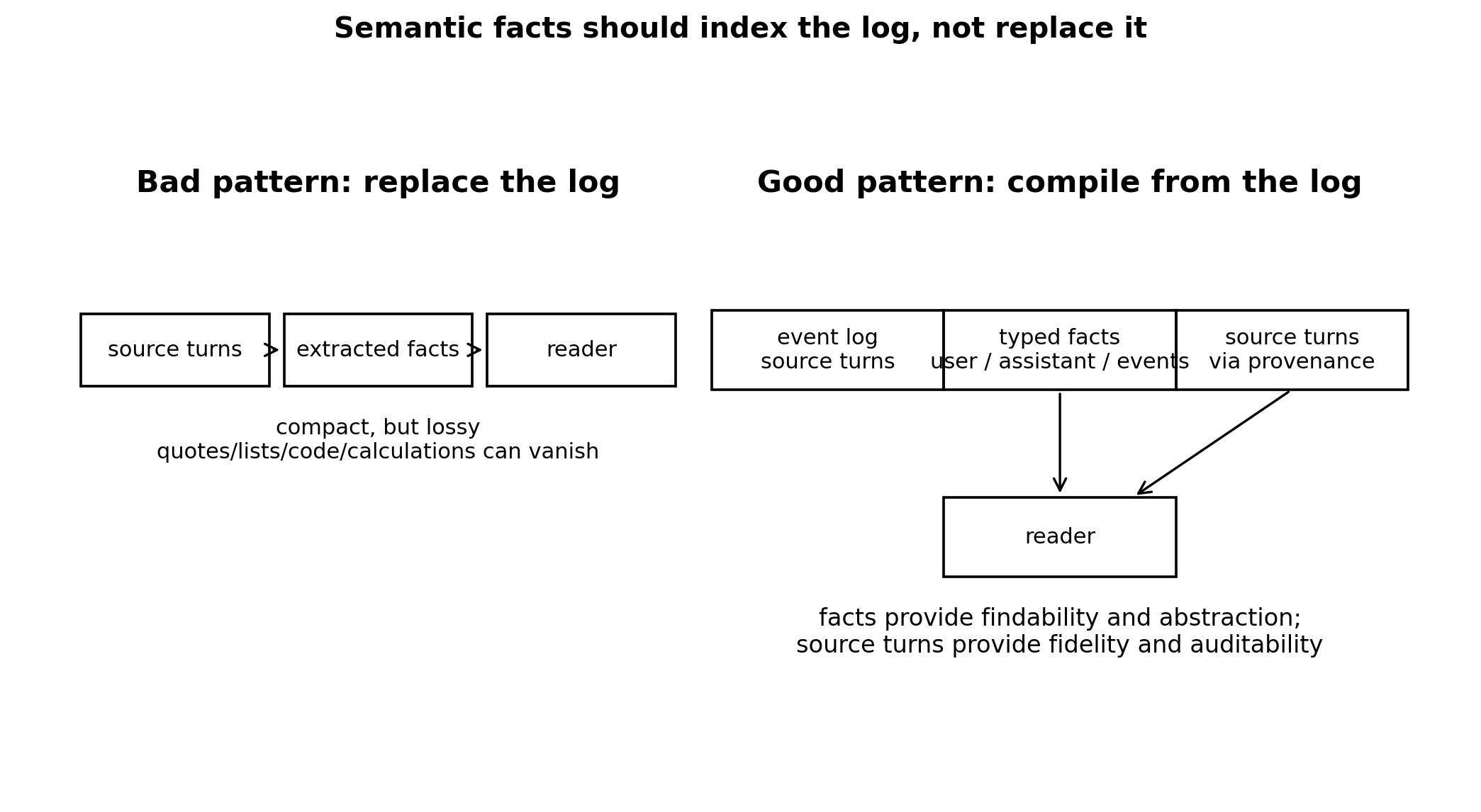
This is the third post in the ActiveGraph LongMemEval-S series. Evidence Compilation Before Semantic Memory showed that the event-sourced substrate can retrieve evidence competitively at compact budget, with no LLM-generated memory at ingest. What Semantic Memory Forgets showed that adding LLM extraction on top is powerful but lossy: a user-centric writer dropped assistant-authored facts entirely, a role-aware fix recovered the targeted failure class, and the remaining errors shifted from retrieval to evidence use and fidelity. That post closed with an architectural prescription:
Semantic memory should compile from the log, not replace it. Retrieve semantic claims, then follow provenance back to raw source spans.
This post tests that prescription. We build a hybrid retrieval system — LLM-extracted facts as a typed retrieval index, with provenance-anchored source turns reaching the reader — and evaluate it on full LongMemEval-S against the post-1 substrate baseline.
The result, in one sentence: the architecture works on retrieval where prior analysis predicted it should, and the QA gain follows where retrieval was binding; what remains is reader-side.
Concretely:
- Aggregate retrieval-side answer-in-context improves significantly: +3.8pp, p = 0.030.
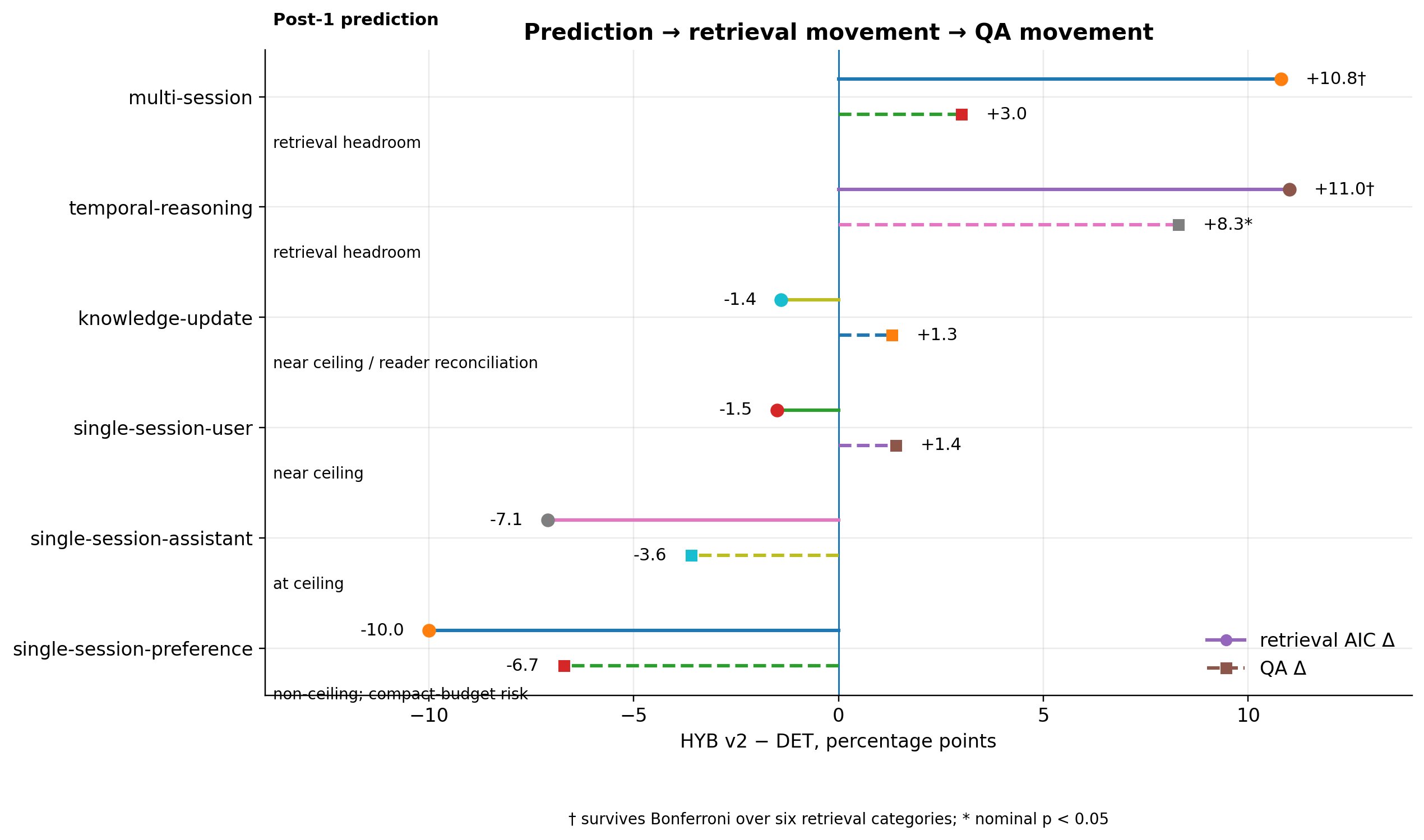
- The significant retrieval gains concentrate in the two main headroom categories identified in post 1: multi-session +10.8pp, p = 0.0072; temporal-reasoning +11.0pp, p = 0.0026. Both survive Bonferroni correction across six per-category retrieval tests.
- Temporal-reasoning QA improves by +8.3pp (p = 0.027), consistent with the retrieval mechanism. Because this does not survive six-way correction across QA categories, we treat it as a mechanism-linked per-category finding rather than a standalone corrected QA claim.
- Aggregate QA is positive but not significant: +2.6pp, p = 0.118.
- The reader-failed-with-evidence count is unchanged but the composition shifts: 37 in each system, with 18 shared IDs and 19 system-specific failures in each direction. Retrieval improvements move some questions from "missing evidence" to "evidence present but misread."
- Directional compact-budget tradeoffs remain diagnostic, not established costs: ss-preference and ss-assistant regress directionally under fixed budget, but neither clears significance.
This is a retrieval validation result, not an aggregate-QA win.
Stage-1 in this work refers to LLM-extracted facts as retrieval indexes with provenance to source turns. Stage-2 would be typed state operations like supersession/current-vs-stale resolution before assembly. This post evaluates Stage-1 only.
1. What is being compared
LongMemEval-S, cleaned s split, n = 500 questions. Across the dataset the haystack consists of 19,195 unique (session_id, content_sha256) pairs; each question's haystack averages ~48 sessions.
Fixed across both systems:
- Reader: Claude Sonnet 4.5 (
claude-sonnet-4-5, resolved snapshotclaude-sonnet-4-5-20250929), temperature 0. - Judge: gpt-4o-2024-08-06, temperature 0.
- Embedding model: text-embedding-3-small.
- Retrieval budget: 2,500 tokens (matched to post 1's compact regime).
- Dataset seed: 42.
Systems
| System | Memory writer | Retrieval pool | Reader sees |
|---|---|---|---|
activegraph-det-embedding | none (raw turns) | Turn | scored turns |
activegraph-sem-hybrid v2 | LLM extraction (user-prompted + assistant-prompted) | Fact (scored, both roles) | fact-as-header + provenance-anchored source turn |
det-embedding is the post-1 substrate — not a weak baseline. In post 1 it reached 85.6% QA accuracy at 2,462 mean context tokens and was statistically tied with dense turn-RAG (McNemar p = 0.132) and with the gold-session oracle. The substrate is the strongest available local comparison for asking whether semantic memory adds anything beyond a capable retrieval substrate.
sem-hybrid v2 writes LLM-extracted facts as typed graph nodes during ingest. Each Fact is linked to its source turn(s) via mentions edges. At retrieval time, facts are scored against the question with embedding cosine; selected facts enter reader context as labeled headers above their provenance-anchored source turns. When multiple facts share a turn, the turn is rendered once with all relevant fact-headers stacked above it. Budget accounting is unified per fact-entry: each entry costs len(fact.text) + sum(len(turn.text) for turn in mentions) tokens.
Role-awareness is a write-time property: two extraction behaviors fire per session at ingest (user-prompted and assistant-prompted), producing facts tagged data["role"] = "user" or "assistant". The retriever does not filter by role; the embedding signal does the discrimination. This is the architectural fix post 2 introduced for the user-centric extraction projection failure, now evaluated at compact budget on full-500 against the substrate, not against itself.
A clarification worth making early: role-aware extraction is not guaranteed to beat raw turns on assistant-targeted questions. Its purpose is to prevent semantic memory from erasing assistant-authored evidence, which is what the user-centric writer did in post 2. Against the raw-turn substrate, single-session-assistant retrieval is already at ceiling (100% AIC); the only visible effect at compact budget is whether the hybrid pool competes effectively for the same retrieval budget. Section 3 reports this directly.
2. Methodology: smoke ablation and cache freezing
The full-500 comparison tests a single hybrid configuration. The choice of that configuration was made via a five-arm smoke ablation on the 50-question smoke subset committed in config/smoke_ids.txt. We report the smoke ablation here as methodology (the design selection process), not as a result.
2.1 The five-arm smoke ablation
All five systems run against the same 50-question smoke subset, same judge, same reader, same 2,500-token budget.
| System | Memory writer | Retrieval pool | Reader sees | Overall (smoke) |
|---|---|---|---|---|
activegraph-det-embedding | none (raw turns) | Turn | scored turns | 0.86 |
activegraph-sem-extract | LLM extraction (user-prompted v1) | Fact | facts only | 0.72 |
activegraph-sem-index | LLM extraction (user-prompted v1) | Fact (scored) | provenance-anchored source turns only | 0.82 |
activegraph-sem-hybrid v1 | LLM extraction (user-prompted v1) | Fact (scored) | fact-as-header + source turn | 0.86 |
activegraph-sem-hybrid v2 | LLM extraction (user + assistant prompted) | Fact (scored, both roles) | fact-as-header + source turn | 0.92 |
Per-category cells are small (n=3 to n=14); the smoke result is directionally informative but n=50 is too small to establish aggregate significance. The smoke serves to select the architecture, not to claim a result.
Three things the smoke decomposition established:
1. Naive replacement loses. sem-extract (replacing turns with extracted facts) regressed 16pp at compact budget vs the substrate. Information loss is real at write time: granularities the extractor prompt compresses (product model numbers, exact phrasings) are answer-bearing at this budget on single-session-user and multi-session questions.
2. Smoke suggests two additive effects. sem-index (facts as retrieval signal, only source turns reach the reader) recovered to 0.82 — much of the recovery from naive extraction's regression comes from facts being a smarter index over turns. sem-hybrid v1 (facts also visible to the reader) recovered to 0.86 — the additional recovery is consistent with the reader benefiting from the abstracted fact text alongside the source turn. Smoke suggests both effects are additive; n=50 is too small to formally establish either independently.
3. Role-aware extraction recovers the assistant-coverage failure. sem-hybrid v1 and sem-index both scored 0/5 on single-session-assistant at smoke — independent reproduction of the post-2 finding on this harness. sem-hybrid v2 recovered ss-assistant to 4/5 by adding an assistant-prompted extraction behavior at ingest. The fix is representational, not retrieval-algorithmic: the embedding signal correctly routes assistant-targeted queries to assistant-prefixed facts without any retrieval or assembler change.
The selected design for full-500 is sem-hybrid v2. The full-500 comparison tests whether the smoke-selected configuration's retrieval and QA effects survive at scale against the substrate baseline, not whether each ablation arm scales independently.
2.2 Cache freezing
Naive LLM extraction at temperature 0 is not deterministic across API calls. Two independent passes of the same prompt over the same input produce overlapping but non-identical fact sets, driven by routing, batching, and other server-side non-determinism outside our control. To preserve the substrate's determinism property under a non-deterministic generative process, we perform extraction once and freeze it as a committed canonical artifact.
Offline measurement on the smoke unique-session set, two independent passes (seed-A and seed-B) at identical prompt SHA and model snapshot: 58.1% of sessions produce byte-identical fact sets; per-corpus stable-core (facts appearing in both passes) is 79%. A meaningful share of the apparent symmetric-difference is paraphrastic rather than semantic.
The full-500 cache (data/sem_extract_cache/seed-A-v2.jsonl, 38,391 entries, prompt SHA 603cd99e657a5412...) is committed to the repository with a stamped manifest recording prompt SHA, extractor model snapshot, file SHA-256, and timestamp. A load-time guard refuses any cache whose prompt SHA or model snapshot does not match the current code. Smoke-portion zero-LLM-call replay was verified.
Cache construction hit an API credit-exhaustion failure mode that silently stubbed some entries with empty facts. We detected it via empty-rate divergence from the smoke baseline, dropped affected entries, re-extracted after credit top-up, and verified final empty rates match smoke within 0.5pp on both roles (user 17.9% vs smoke 17.5%; assistant 10.3% vs smoke 11.0%). The committed cache is clean; the underlying script fix is to retry network errors before stubbing.
3. Results
3.1 QA accuracy
| Category (n) | DET | HYB v2 | Δ | b−c | p (McNemar) |
|---|---|---|---|---|---|
| OVERALL (500) | 0.850 | 0.876 | +0.026 | +13 | 0.118 |
| single-session-user (70) | 0.943 | 0.957 | +0.014 | +1 | 1.000 |
| single-session-preference (30) | 0.867 | 0.800 | −0.067 | −2 | 0.688 |
| single-session-assistant (56) | 1.000 | 0.964 | −0.036 | −2 | 0.500 |
| multi-session (133) | 0.789 | 0.820 | +0.030 | +4 | 0.503 |
| temporal-reasoning (133) | 0.767 | 0.850 | +0.083 | +11 | 0.027 |
| knowledge-update (78) | 0.897 | 0.910 | +0.013 | +1 | 1.000 |
b is HYB-only correct; c is DET-only correct; b−c is net paired gain in HYB's favor.
Aggregate QA difference is not statistically significant at α = 0.05. Exact McNemar on 59 discordant pairs (b=36, c=23) gives p = 0.118. The +13-question net advantage is directionally positive but within the noise band at this sample size.
Temporal-reasoning is nominally significant at α = 0.05 (p = 0.027). On n=133, HYB v2 picks up 16 questions DET missed against 5 the other way. We treat this as mechanism-linked to the retrieval result reported in §3.2 — the category where retrieval was binding on the substrate — rather than as a standalone six-way-corrected QA claim.
No other per-category QA test reaches significance. The role-aware fix from post 2 is not visible as a QA improvement on single-session-assistant because the substrate is at ceiling there (56/56); the small directional regression (52/56 → 54/56) reflects compact-budget competition between the user-fact and assistant-fact retrieval pools, not a failure of role-aware extraction itself.
3.2 Retrieval-side answer-in-context
We use the canonical AIC metric from post 1: a question is a turn-AIC hit iff the system's retrieved turn-IDs are a superset of the gold turn-IDs (turns flagged has_answer in the dataset). Where turn-level gold is undefined, session-level fallback is used (gold session-IDs ⊆ retrieved session-IDs).
| Category (n) | Prediction from post 1 | DET turn-AIC | HYB v2 turn-AIC | Δ | b−c | p (McNemar) |
|---|---|---|---|---|---|---|
| OVERALL (470) | — | 86.2% | 90.0% | +0.038 | +18 | 0.030 |
| single-session-user (64) | near ceiling | 98.4% | 96.9% | −0.015 | −1 | 1.000 |
| single-session-preference (30) | non-ceiling | 80.0% | 70.0% | −0.100 | −3 | 0.453 |
| single-session-assistant (56) | at ceiling | 100.0% | 92.9% | −0.071 | −4 | 0.125 |
| multi-session (121) | retrieval headroom | 76.0% | 86.8% | +0.108 | +13 | 0.0072 |
| temporal-reasoning (127) | retrieval headroom | 79.5% | 90.6% | +0.110 | +14 | 0.0026 |
| knowledge-update (72) | near ceiling / reader reconciliation | 95.8% | 94.4% | −0.014 | −1 | 1.000 |
DET turn-AIC reproduces post 1's per-type sidecar numbers; the "prediction" column summarizes post 1's characterization of where headroom was expected.
Aggregate retrieval-side AIC is significantly improved at α = 0.05 (p = 0.030). +18 paired retrieval-side wins to HYB v2 on 62 discordant pairs.
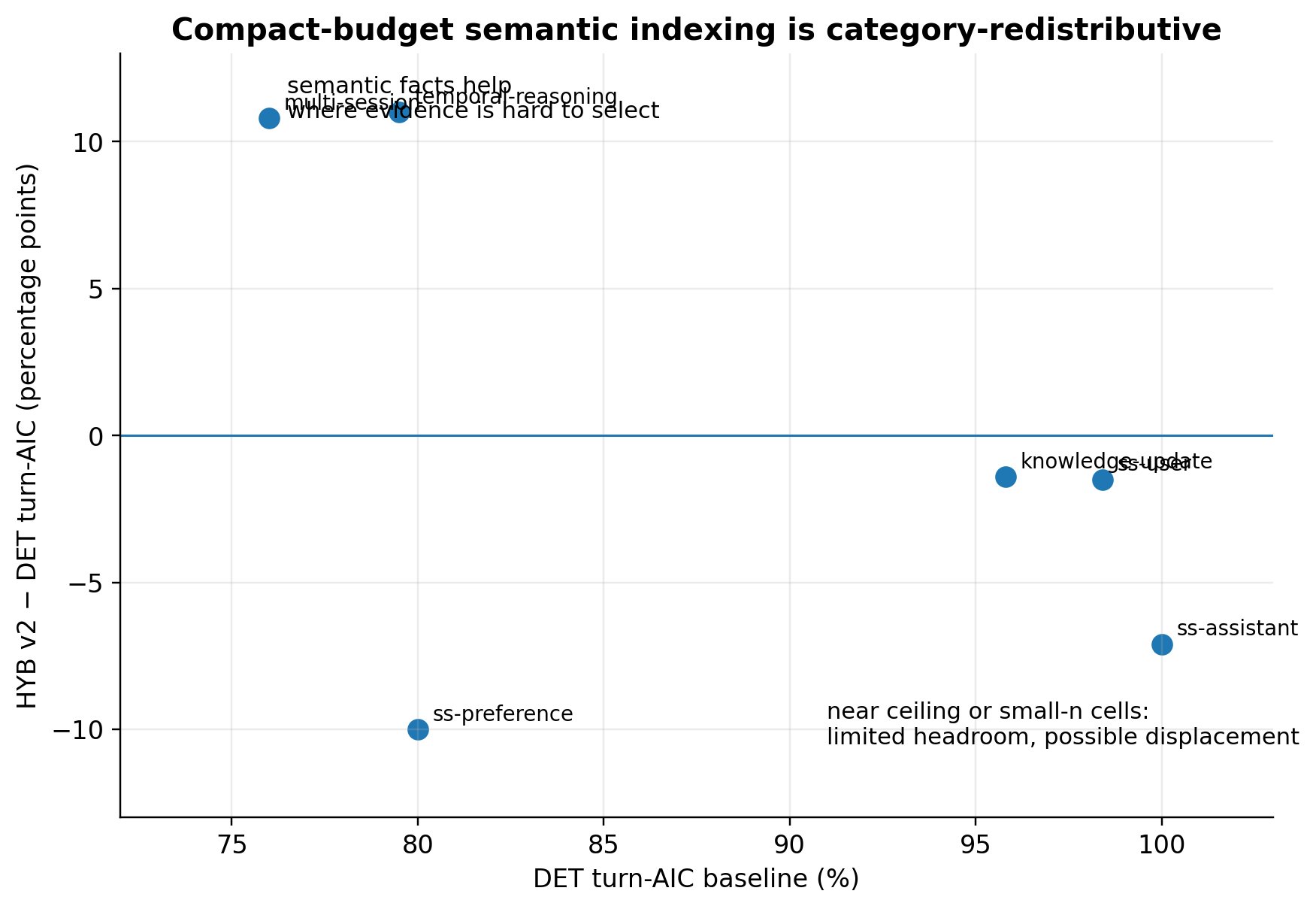
The two categories post 1 identified as the main retrieval-headroom categories — multi-session and temporal-reasoning — are both significant at α = 0.01. Effect sizes are large: +10.8pp and +11.0pp respectively. Both survive Bonferroni correction across six per-category tests (corrected α ≈ 0.008): multi-session p = 0.0072 ✓, temporal-reasoning p = 0.0026 ✓.
Single-session-preference also has non-ceiling turn-AIC at the substrate (80%) — it is not a near-ceiling category — but the small n and directional regression under HYB make it a design diagnostic rather than a validated positive or negative result.
The categories where post 1 reported retrieval at or near ceiling (knowledge-update 95.8%, ss-user 98.4%, ss-assistant 100%) all show small changes that do not reach significance.
The larger directional regressions, ss-preference (−10.0pp) and ss-assistant (−7.1pp), trend in the compact-budget competition direction characterized at smoke (assistant-fact pool dilutes user-fact ranking under a fixed retrieval budget) but do not clear significance at their respective n = 30 and n = 56. We treat them as design diagnostics, not result claims. ss-user moves −1 paired AIC hit and should be treated as noise.
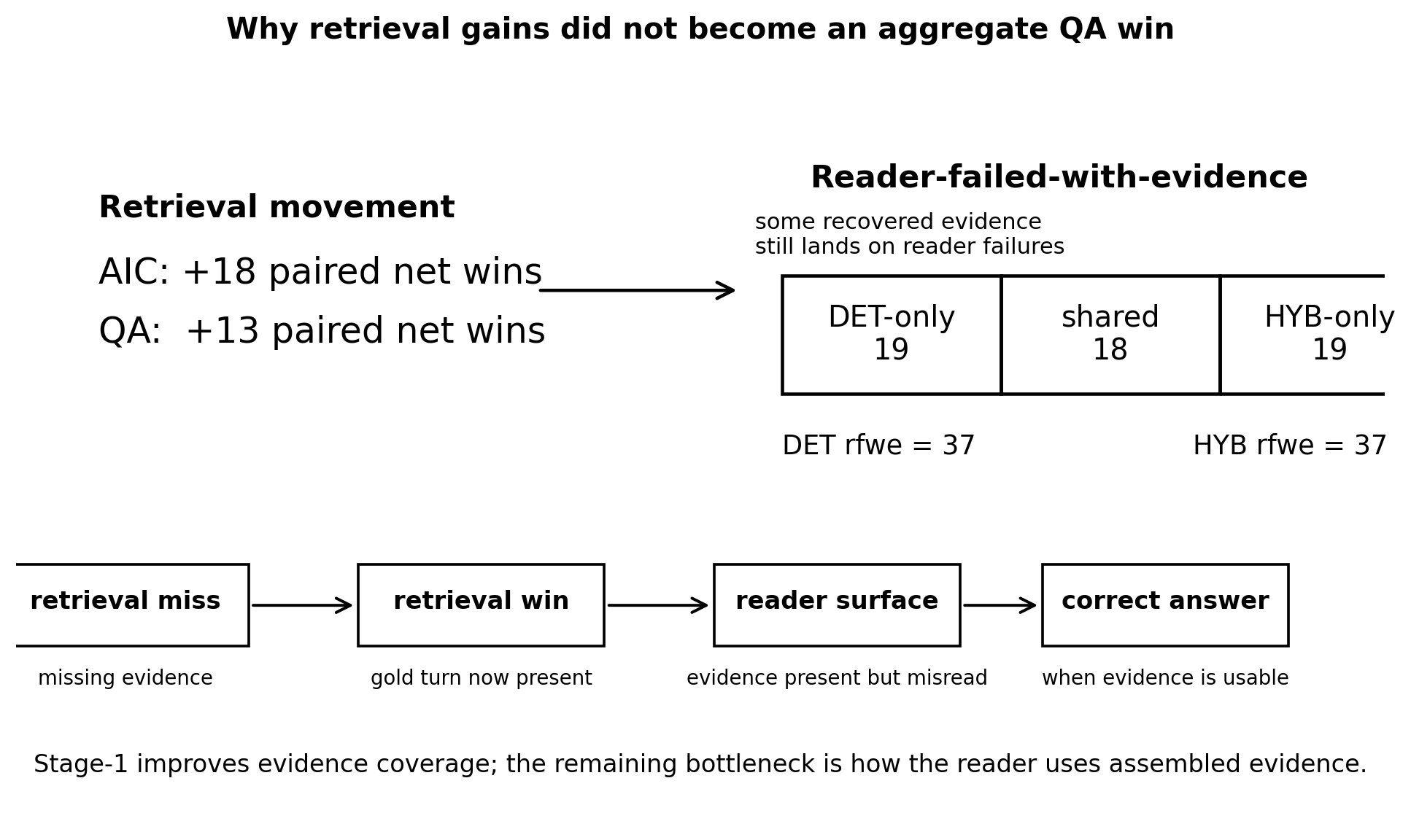
3.3 Reader-failed-with-evidence
A critical secondary measurement, following post 1's convention: how often does the reader judge wrong when retrieval surfaced the gold turn? We count reader_failed_with_evidence (rfwe) as questions where the judge marks the hypothesis wrong but the AIC turn-hit (or session-hit fallback) is true.
| System | rfwe count |
|---|---|
| det-embedding | 37 |
| sem-hybrid v2 | 37 |
The count is identical. The question-ID overlap is partial:
- 18 questions are rfwe in both systems (49% overlap).
- 19 questions are rfwe in DET only.
- 19 questions are rfwe in HYB v2 only.
This is not a "the reader bottleneck is the same in both systems" finding. The reader-failure count is identical but the composition differs substantially. The 18 shared questions reflect a content-driven reader floor — questions that confound the reader regardless of which retrieval pipeline assembled the context. The 19+19 system-specific failures indicate that which evidence reaches the reader interacts with reader behavior even when the gold turn is retrieved: improving retrieval can shift the failure set without changing its size.
This complicates the simple story: even though aggregate retrieval improves significantly (§3.2), about half of the retrieval improvements convert questions from retrieval-miss to evidence-present-but-misread rather than to correct answers, because they intersect a reader-side failure mode the semantic layer does not address.
4. Reading the numbers together
The four findings interlock:
1. The architectural prescription is supported on the retrieval side. Hybrid retrieval — facts as a typed index over the event log, with provenance back to source turns — significantly improves aggregate turn-level retrieval coverage (+3.8pp, p = 0.030).
2. The significant retrieval gains concentrate in the two main headroom categories from post 1. Multi-session retrieval improves +10.8pp (p = 0.0072) and temporal-reasoning retrieval improves +11.0pp (p = 0.0026) — these were the two categories post 1 identified as the main retrieval-headroom cases. Both effects survive multiple-comparisons correction.
3. The retrieval gain converts to QA gain on the category where retrieval was the binding constraint. Temporal-reasoning QA improves +8.3pp (p = 0.027), mechanism-linked to the retrieval improvement on the same category. Multi-session retrieval improves significantly (p = 0.0072) but its QA gain (+3.0pp) does not clear significance — likely because the marginal multi-session questions recovered by retrieval intersect the reader-failure set characterized in §3.3.
4. Aggregate QA is +2.6pp positive but not significant (p = 0.118). Two larger small-n directional retrieval regressions (ss-pref, ss-asst), plus one effectively unchanged ss-user cell, appear in the table; only ss-pref and ss-asst trend in the budget-competition direction post 2 characterized, and neither clears significance. The rfwe composition shifts but its size does not. The combination — significant retrieval gain + composition-dependent reader-failure shifting + small-n diagnostics — produces a positive aggregate trend without aggregate significance.
This is the architecture behaving as its theoretical motivation predicted on the retrieval side, with the remaining QA failures localized to a reader/evidence-use surface that the Stage-1 retrieval architecture does not directly address.
5. What is and isn't claimed
Claimed
-
At matched 2,500-token budget on full-500, sem-hybrid v2 significantly improves aggregate turn-level retrieval coverage over the post-1 substrate (+3.8pp, p = 0.030 by exact McNemar on 470 paired questions).
-
Retrieval improvement is concentrated on the two main retrieval-headroom categories identified in post 1: multi-session (+10.8pp, p = 0.0072) and temporal-reasoning (+11.0pp, p = 0.0026), both significant at α = 0.01 and surviving Bonferroni correction across six per-category tests.
-
Temporal-reasoning QA accuracy is nominally significant at α = 0.05 (+8.3pp, p = 0.027). This is the category where retrieval was the binding constraint at the substrate baseline; the QA gain follows the retrieval gain. We treat it as mechanism-linked to the retrieval result rather than as a standalone corrected per-category QA claim.
-
The reader-failed-with-evidence count is identical across systems (37 each) but only 49% of the question IDs overlap. The shared-18 set reflects a content-driven reader floor; the 19+19 system-specific failures reflect composition-dependent reader behavior. Aggregate retrieval improvement does not translate one-for-one into aggregate QA improvement because some retrieval wins intersect the reader-failure surface.
-
Determinism is preserved. LLM-extracted facts are written as events and frozen as committed artifacts with prompt + model-snapshot provenance. The substrate operating on the committed log is byte-identical on rerun.
Not claimed
-
Aggregate QA improvement is not statistically established at n = 500 (+2.6pp, p = 0.118). The trend is positive; the effect does not reach significance.
-
The directional retrieval regressions on ss-preference (−10.0pp) and ss-assistant (−7.1pp) are not statistically establishable at their sample sizes. The direction is consistent with the budget-competition mechanism characterized at smoke; at n = 30 and n = 56 the effect does not clear significance. We treat these as design diagnostics, not result claims.
-
Graph topology is not established as the causal mechanism. As in post 1, the unit of comparison is the full evidence-compilation pipeline (indexing, scoring, expansion, packing, ordering, rendering). This experiment does not isolate the contribution of graph structure vs. typed facts vs. provenance edges vs. role-aware writing.
-
The Stage-2 supersession hypothesis is not tested. Knowledge-update retrieval is at ceiling on both systems (95.8% / 94.4% turn-AIC, within sampling noise), consistent with post 1's prediction. Whether explicit supersession marking would help here remains an open question; the Stage-1 retrieval saturation makes it hard to test on LongMemEval-S and would require a benchmark where the user's stated facts genuinely change across sessions.
-
The temporal-reasoning QA gain (p = 0.027) would not survive Bonferroni correction across six per-category QA tests (corrected α ≈ 0.008). It is reported as a per-category finding consistent with the predicted retrieval mechanism, not as a stand-alone significance claim independent of the retrieval result.
-
No external-judge robustness check. A single judge (
gpt-4o-2024-08-06) is used across all comparisons; this is internally consistent but not externally validated.
6. Limitations and follow-ups
Reader-bottleneck composition. The §3.3 finding — 37 rfwe in both systems, 18 shared question IDs, 19+19 system-specific — is more nuanced than "the reader is the bottleneck." Improving retrieval shifts which questions become reader-bottlenecked. The next investigation should characterize the 19 HYB-only rfwe questions: are they cases where the assembled context now contains more competing evidence than the reader can adjudicate? Cases where the fact-as-header changes how the reader weights source turns? Per-example audits would isolate this.
Budget competition diagnostic. The directional retrieval regressions on ss-preference (−10.0pp) and ss-assistant (−7.1pp), though not significant, are direction-consistent with the smoke characterization of compact-budget competition between the user-fact and assistant-fact retrieval pools. A clean diagnostic experiment is a budget sweep: hold both systems fixed at 5,000 and 10,000 tokens and measure whether the regressions disappear at larger budgets. The hypothesis is not "larger budget makes aggregate QA significant" — it could go either way, because larger budgets also give the substrate more raw-turn room. The hypothesis is that if compact-budget pool competition is the mechanism for the ss-pref/ss-asst regressions, the regressions should attenuate at larger budgets while the multi-session and temporal-reasoning gains persist. Either outcome is informative; neither is guaranteed.
Borges fidelity. Post 2 identified a residual fidelity-loss failure mode where extraction paraphrases the assistant's verbatim output (a Borges quote) and the exact span is lost. Stage-1 hybrid partially mitigates this by rendering the source turn alongside the fact header when the source turn is selected by retrieval. A provenance-backed verbatim-fallback experiment — for quote, list, code, and calculation questions, follow mentions edges back to the raw span regardless of budget pressure — is the natural extension. The small directional retrieval regression on ss-assistant at full-500 is compatible with this failure family, but the post does not establish that Borges-like fidelity loss is the dominant cause.
Single seed. Only seed-A-v2 was scored at full-500. Offline fact-level variance (smoke set) shows 79% stable-core across independent extractions; whether the score-level result is stable across re-extractions remains untested. A two-seed variance band at smoke (seed-B-v2, seed-C-v2) is the cheapest follow-up.
Stage-2 supersession. Knowledge-update retrieval is at ceiling on both systems on LongMemEval-S, making supersession-mechanism testing on this dataset uninformative. A multi-session-with-state-change benchmark (where the user's stated preferences or facts genuinely conflict across sessions and the reader must reconcile) is the right next setting.
Multiple comparisons. The two primary per-category retrieval claims (multi-session p = 0.0072, temporal-reasoning p = 0.0026) survive Bonferroni correction across six per-category tests (corrected α ≈ 0.008). The temporal-reasoning QA claim (p = 0.027) does not, and is reported as mechanism-linked rather than as a stand-alone significance claim. The aggregate retrieval (p = 0.030) and aggregate QA (p = 0.118) are reported as primary endpoints with α = 0.05.
The shape of remaining error
The lesson is not that semantic memory should replace deterministic evidence compilation. The lesson is that semantic memory becomes useful when it remains accountable to the source log. Facts provide handles; source turns provide fidelity; the reader still needs better evidence-use operators. Stage-1 gets the right evidence into the room. The next layer decides what to do with it.
What full-500 clarifies is where Stage-1 stops helping. After hybrid retrieval surfaces gold turns on multi-session and temporal-reasoning questions, the remaining errors look less like "missing memory" and more like reader-side evidence use: the answer-bearing turns are present, the reader still fails. The §3.3 composition finding sharpens this — improving retrieval does not subtract from the reader-failure surface, it shifts which questions sit on it. The evidence-present wrong set is the natural next target: these are not retrieval failures, but reader/assembly failures, and the experiments that would address them are different in kind from this one.
7. Reproduction
Branch claude/loving-bohr-4x2nK. Run dirs under runs/. Cache at data/sem_extract_cache/seed-A-v2.jsonl (committed d2bdbb4, 38,391 entries); SHA pinned in CHECKSUMS.sha256.
git clone https://github.com/yoheinakajima/activegraph-longmemeval
cd activegraph-longmemeval
git checkout claude/loving-bohr-4x2nK
make setup && make data
# Verify the committed cache (no API spend).
uv run python scripts/verify_extract_cache.py --seed A-v2
# Reproduce the full-500 scored comparison.
uv run python -m activegraph_lme.cli run --system activegraph-det-embedding --dataset s
uv run python -m activegraph_lme.cli run --system activegraph-sem-hybrid --dataset s --extract-seed A-v2
# Eval, AIC sidecar + scorer for each run.
for d in $(ls -dt runs/*activegraph-*__s__full/ | head -2); do
uv run python -m activegraph_lme.cli eval --run-dir "$d"
uv run python scripts/aic_sidecar.py "$d"
uv run python scripts/answer_in_context.py "$d"
done
Both systems share reader, judge, embedding model, retrieval budget, and dataset seed. The committed seed-A-v2.jsonl produces zero LLM extraction calls during scored runs.
8. References
- Yohei Nakajima, Evidence Compilation Before Semantic Memory: ActiveGraph on LongMemEval-S, 2026.
- Yohei Nakajima, What Semantic Memory Forgets: ActiveGraph on LongMemEval-S, 2026.
- Yohei Nakajima, The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems, 2026.
- Di Wu et al., LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory, ICLR 2025.
- Nelson F. Liu et al., Lost in the Middle: How Language Models Use Long Contexts, TACL 2024.
- Cheng-Yu Hsieh et al., Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization, ACL Findings 2024.
- Preston Rasmussen et al., Zep: A Temporal Knowledge Graph Architecture for Agent Memory, 2025.
- Prateek Chhikara et al., Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025.
← back to blog