ActiveGraph Packs: A Composable Assistant Substrate
A reference pack library for graph-native assistants — memory, identity, tools, comms, and domain capabilities composing through evented state instead of a central orchestrator.
- activegraph
- packs
- agents
- assistant
- event-sourcing
TL;DR
activegraph-packsis a reference pack library for building graph-native assistants on ActiveGraph.- A small seven-object Core (
source,observation,task,action,artifact,memory_candidate,evaluation) is the only shared vocabulary; every other pack maps back to it.- Layered packs cover infrastructure (tools, secrets, memory, identity, agent profile, entity), communication (channel-neutral comms, chat, email), and domain (research, VC, codebase, team ops, meeting), plus bridges.
- Packs compose through graph state, not function calls — no central coordinator, just behaviors reacting to evented state.
- Bundles (
assistant,email_assistant,vc_bundle,research_bundle) are preset load orders, not a third ontology.- The repo is the substrate-level companion to AG Coder, Deep Research, Regimes, and the selfgraph / BehaviorDrafts work in Code Without Authority and Self-Modification is Not Binary.
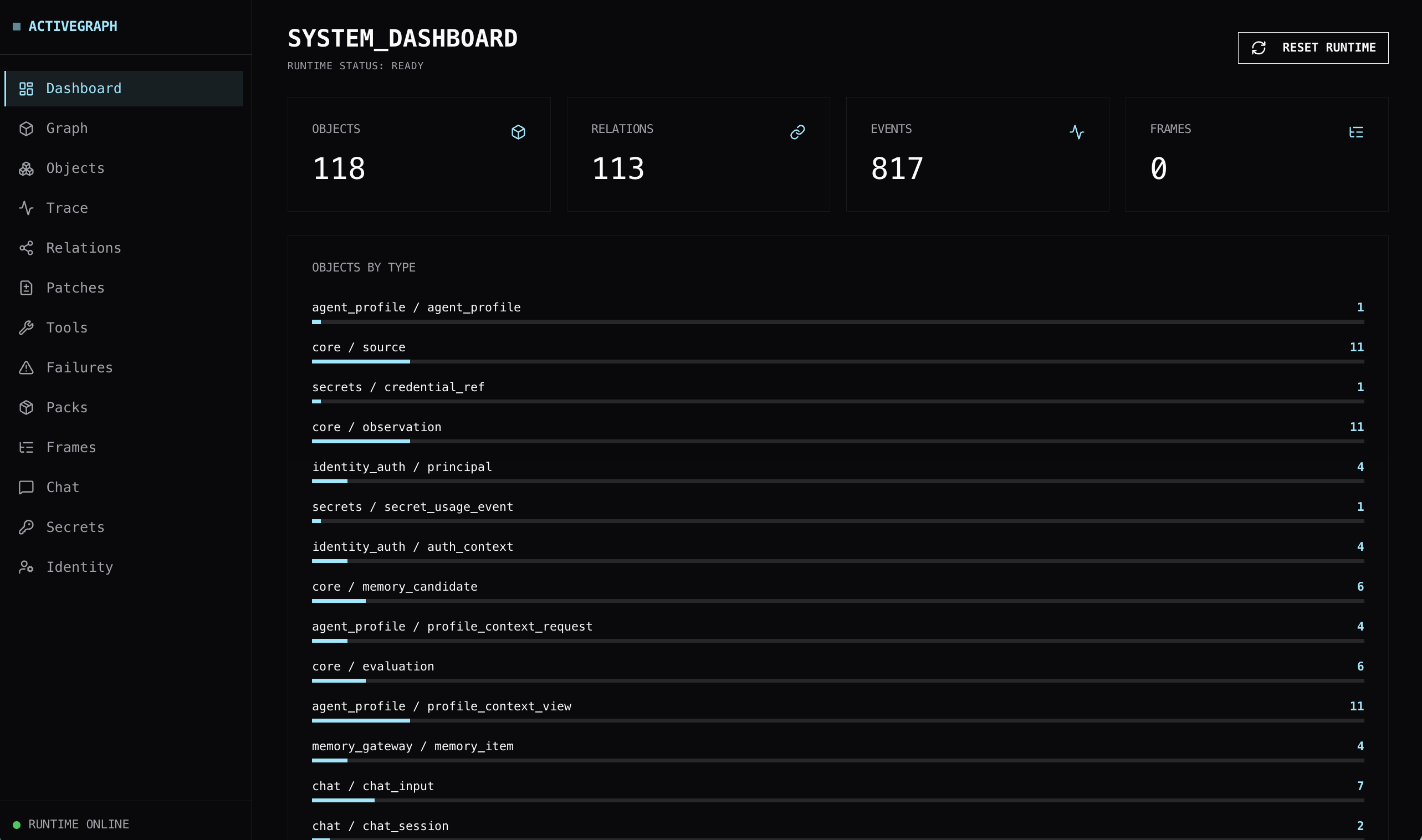
I have been building a set of ActiveGraph reference applications to make the runtime easier to understand.
AG Coder showed what a coding agent looks like when plans, tasks, model calls, file reads, patches, test runs, approvals, and failures are graph state instead of an opaque transcript. ActiveGraph Deep Research showed the same pattern for research: sources, evidence spans, claims, report sections, and lineage as first-class objects rather than a flattened report. selfgraph and BehaviorDrafts (see Code Without Authority and Self-Modification is Not Binary) explored the self-modification side: proposals, forks, diffs, promotion, and authority boundaries as event-sourced state.
Each of those answers one question: what does a graph-native agent look like inside a specific workflow? The next question is composition.
A useful assistant is not one workflow. It receives messages, understands identity, remembers preferences, retrieves context, uses tools, drafts responses, asks for approvals, manages tasks, summarizes meetings, reads code, tracks research, and knows when a domain-specific pack should participate. It looks less like a single agent loop and more like an operating surface for many capabilities.
The usual way to build that surface is to put a coordinator in the middle. A chat message comes in; the coordinator decides which tools are available, retrieves memory, assembles context, calls a model, executes actions, writes logs, and updates state. It works until the surface grows. Then the coordinator becomes the place where every concern is centralized at once — memory governance, identity, policy, domain knowledge, response shape, audit. activegraph-packs is a different bet: keep the coordinator out, and let capabilities compose through graph state.
What a pack actually is
A pack is a small reactive vocabulary plus the behaviors that make that vocabulary live. It adds a namespace, object types, relations, behaviors, tools, prompts, policies, fixtures, and documentation — not just a callable endpoint.
The Core Pack is deliberately tiny. It defines the seven universal primitives every other pack can speak — source, observation, task, action, artifact, memory_candidate, evaluation — and nothing else. No people, companies, claims, documents, emails, meetings, or repos. Those belong above Core.
Layered packs own the domain nouns. communication owns channel-neutral messages; email owns threading and draft formatting; identity_auth owns principals and permissions; memory_gateway owns memory acceptance and retrieval; vc owns venture objects; research owns papers, hypotheses, claims, and results; codebase owns repos, issues, PRs, files, and architecture decisions. They all map back to Core: a VC pack can create a founder email, but it also emits Core observations, tasks, artifacts, evaluations, actions, and memory candidates. That mapping is what lets infrastructure packs work without knowing every domain pack exists.
Packs compose through graph state, not direct calls. One pack writes an object, that write becomes an event, and a behavior in another pack reacts to the event. There is no central orchestrator deciding the global flow. Bundles sit on top as named load orders with defaults — assistant, email assistant, VC assistant, research assistant — with no ontology of their own.
The practical result is close to the open-source personal-assistant shape people are excited about right now — chat, email, tools, memory, actions, domain skills — but with a different internal substrate. The assistant is a graph-visible composition of packs over a replayable event log, not a gateway wrapped around hidden state.
Why packs, not one big assistant?
The product is obvious. People want to say something in chat, email, Slack, Telegram, WhatsApp, voice, or an API, and have the assistant know who they are, what it is allowed to do, what they have done before, what tools exist, what context matters, and what should happen next. They want it to clear an inbox, draft a reply, summarize a meeting, follow up with a founder, prepare diligence, inspect a codebase, schedule something, or remember a preference.
The hard part is not imagining that assistant. The hard part is keeping it legible once it becomes useful.
A simple version is a loop:
receive message
load user profile
retrieve memory
select tools
call model
execute tool calls
append observations
maybe send response
repeat
That loop works until every step grows a sub-system. Memory becomes candidate extraction, acceptance, dedupe, storage, retrieval, ranking, expiration, and sync. Tools become capability discovery, permission checks, credential injection, execution records, failures, retries, and audit. Communication becomes channel adapters, threads, intents, response candidates, delivery states, and approval gates. Identity becomes principals, roles, permissions, delegated authority, and source resolution. Domain work becomes research, VC, code, meetings, finance, operations, support, or whatever the assistant is actually supposed to know.
At that point the loop is no longer the thing you're building. It's where everything got accidentally centralized.
ActiveGraph's answer is to move the substrate down a layer. The event log is the source of truth. The graph is the current projection of that log. Behaviors react to events and graph patterns. Tools and model calls are runtime events. State transitions are typed objects and relations. UIs, reports, memories, and traces are projections.
That inversion is why composition no longer has to mean orchestration. A chat pack doesn't call the memory_gateway pack — it emits a communication/message and a Core source. A memory behavior reacts if its view asks for memory. An identity behavior resolves the source into a principal. A domain pack reacts when enough context exists. An email pack drafts a response candidate. A tool gateway turns an approved action into execution. The cascade isn't hidden in a coordinator; it's visible in the graph. The assistant becomes a set of reactive capabilities sharing a substrate.
A pack is not a plugin
A plugin adds a function to something else. A pack defines part of the world the assistant operates over.
A pack can contain:
object types
relation types
behaviors
LLM behaviors
tools
prompts
settings
fixtures
policies
README / changelog / examples
The difference is that a pack defines typed state and the behaviors that respond to it, not just a callable signature. In a conventional framework, a "calendar plugin" exposes:
create_event(...)
list_events(...)
cancel_event(...)
Useful — but the assistant still needs a coordinator to decide when to call them, how to represent their results, how to relate them to a message, whether the user had authority, what memory to update, and what artifact was produced.
In ActiveGraph, a meeting pack participates in a graph instead. A message creates a source. The communication pack identifies a scheduling intent. The identity pack resolves the requester. The meeting pack creates a proposed meeting object. The tool gateway represents the calendar write as an action. The action gets approved, executed, denied, or retried. The result becomes an observation, artifact, memory candidate, or follow-up task.
The tool call is one piece. The state around the tool call is the assistant. That's why packs need schemas and behaviors, not just function signatures.
Core should stay boring
The center of activegraph-packs is the Core Pack: seven object types (and seven matching relation types).
source
observation
task
action
artifact
memory_candidate
evaluation
That list is intentionally boring.
A source is something the system received or grounded on: a message, email, file, web page, API result, meeting transcript, code diff, or external object — the input and provenance side of the graph. An observation is something the system believes it observed or derived: a fact, extracted detail, status, signal, claim-like assertion, or normalized interpretation. A task is intended work: something to do, inspect, draft, verify, follow up on, or decompose. An action is an operation the system may take or did take: send an email, call a tool, run a command, create a calendar event, open a PR, fetch a page, ask for approval. An artifact is durable output: a memo, summary, draft, report, plan, patch, analysis, response candidate, or generated file. A memory_candidate is something that might be worth remembering but has not automatically become memory — the same discipline as BehaviorDrafts, where proposing state and granting durable authority are different operations. An evaluation is a judgment over something else: quality, risk, correctness, permission, confidence, freshness, relevance, pass/fail, or approval status.
That's enough to coordinate many domains without pretending Core is a universal ontology.
This is the part I'd be most careful not to overbuild. The temptation is to add useful nouns to Core: person, company, document, claim, evidence, email, meeting, project, repository, decision. They're all useful. They're also all domain nouns. The moment Core owns them, every domain pack has to either accept Core's meaning or fight it. A VC pack's company_profile, a research pack's paper, a codebase pack's repo, and an entity pack's organization overlap, but they are not the same concept. Forcing them into one Core type early makes the system look cleaner and the semantics worse.
So Core stays a narrow bridge layer that lets packs compose:
vc/company_profile → core/observation
research/claim → core/observation
meeting/action_item → core/task
email/draft → core/artifact
tool_gateway/tool_call → core/action
agent_profile/preference → core/memory_candidate
diligence/risk → core/evaluation
The payoff: infrastructure packs only need to understand Core. A memory system doesn't need to know what a venture memo is — it evaluates memory_candidate. An audit UI doesn't need every domain type — it walks from sources to observations to artifacts and evaluations. A policy layer doesn't need every tool — it inspects proposed actions. A replay or fork system doesn't care which pack created an event — it replays the same log. Core stays small so everything else can be specific.
The layered packs
The repo splits layered packs into four rough groups: infrastructure, communication, domain, and bridge.
core
├── infrastructure
│ ├── tool_gateway
│ ├── secrets
│ ├── memory_gateway
│ ├── identity_auth
│ ├── agent_profile
│ └── entity
├── communication
│ ├── communication
│ ├── chat
│ └── email
├── domain
│ ├── research
│ ├── vc
│ ├── codebase
│ ├── team_ops
│ └── meeting
└── bridges
└── diligence_core_bridge
Fifteen packs plus a bridge — sixteen entry points in total. The split matters more than the specific set.
Infrastructure packs provide capabilities most assistants need, regardless of domain. tool_gateway is the execution boundary: external APIs, MCP calls, and local tools pass through a gateway that normalizes inputs, checks policy, records proposed and executed actions, and emits graph-visible results. secrets handles credential references, with one firm rule — secrets never become prompt context or graph content; they're referenced in graph state and injected only when an approved tool execution needs them. memory_gateway owns the memory lifecycle: Core can say "this might be worth remembering," and the gateway decides whether to accept, how to store, how to retrieve, how to rank, and whether to sync. identity_auth resolves sources into principals and permission contexts, because a long-running assistant can't treat all messages as equal — who said something, through which channel, under what authority, with what delegated permissions, all become graph state. agent_profile owns assistant identity and standing instructions, scoped by audience, channel, and context rather than one global personality blob; the assistant shouldn't speak to a founder, an LP, a child, a teammate, and a GitHub issue in the same mode. entity handles canonical real-world entities — people, organizations, projects, products, repos — the dedup and identity layer for things the assistant encounters across domains.
Communication packs separate semantic messaging from channels. communication owns the channel-neutral concepts — thread, message, intent, response candidate, delivery status, turn/frame context — and doesn't care whether the message came from chat, email, SMS, Slack, or an API. chat and email are adapters: they translate channel-specific inputs into shared communication objects and translate response candidates back out. Email carries its own threading, dedupe, drafts, recipients, formatting, and approval concerns; chat has different interaction patterns. Both speak communication plus Core.
Domain packs own real work. research owns hypotheses, papers, claims, evidence, and results. vc owns founders, companies, deals, theses, and portfolio context. codebase owns repos, files, PRs, architecture notes, and code-related tasks. team_ops owns standing teams, recurring rituals, projects, and operational work. meeting owns transcripts, action items, decisions, and follow-ups. Each domain pack defines its own vocabulary and behaviors, and maps back to Core so infrastructure packs participate without knowing the domain.
Bridge packs translate between layered packs when they need to share semantics. diligence_core_bridge is the canonical example: a diligence-style domain pack emits its own typed outputs (risks, signals, comparisons, references), and the bridge maps those into Core observations, artifacts, and evaluations so they're legible to memory, audit, and review surfaces.
How packs compose
The most important invariant is simple:
Packs compose through graph state, not function calls.
That's not an implementation detail. It's the architectural claim. Take an email review assistant for a VC workflow. The centralized version reads cleanly:
handle_email(email):
sender = resolve_sender(email)
company = lookup_company(sender)
memories = retrieve_memories(sender, company, email)
intent = classify_intent(email)
vc_context = build_vc_context(company)
draft = call_model(email, sender, company, memories, intent, vc_context)
maybe_send(draft)
Readable — and exactly where the system starts to centralize. The ActiveGraph version is a cascade:
email received
→ email pack creates email/thread objects
→ communication pack creates message + intent candidates
→ core/source is created
→ identity_auth resolves principal and permissions
→ entity resolves sender, company, project
→ agent_profile selects relevant standing instructions
→ memory_gateway retrieves relationship and decision context
→ vc pack creates company/founder/deal observations
→ tool_gateway proposes external lookups if needed
→ response candidate is created
→ evaluation checks risk, tone, permission, completeness
→ email pack formats draft
→ action is proposed: send / archive / label / follow up
→ human approval or policy gate decides execution
The difference isn't style. In the first version, every step is a line in a coordinator. Add a meeting pack, you modify the coordinator. Add a better memory pack, you modify the coordinator. Want replay, you reconstruct from logs. Want to know why the draft said something, you chase local variables, model prompts, tool results, and memory calls that may or may not have been recorded consistently.
In the ActiveGraph version, each step is graph-visible and each pack owns a narrow responsibility. The email pack doesn't need to know how VC diligence works. The VC pack doesn't need to know how drafts are formatted. The memory pack doesn't need to know what a founder email is. The identity pack doesn't need to know what the assistant will say. The shared object graph is the coordination surface.
That's what makes the architecture composable in the stronger sense. Remove vc and you still have an email assistant. Add meeting and meeting action items become Core tasks. Swap memory backends without touching the domain pack. Add a verifier behavior that reacts to response candidates and writes evaluations. Add a policy behavior that blocks send actions above a risk threshold. Build a new UI projection over the same trace. The assistant grows by adding behavior around state, not by expanding a central loop.
Prompt context should be behavior-local
One of the traps in assistant architecture is the global context blob. A message arrives, the system builds a giant prompt — recent messages, memories, user profile, tool list, domain notes, calendar data, CRM records, policies, whatever might be relevant — and every model call inherits some version of it. Convenient early, dangerous later.
Different behaviors need different views. A behavior drafting an email reply needs the current message, thread history, sender identity, relationship memory, relevant company context, response style, allowed actions, and communication policy. A behavior deciding whether to remember something needs the candidate, its provenance, existing memories, conflict checks, and acceptance policy. A behavior proposing a tool action needs the task, available capabilities, permission context, budget, and execution policy. A behavior summarizing a meeting needs transcript segments, participants, decisions, open tasks, and previous related meetings. Those are not the same prompt.
In ActiveGraph terms, an LLM behavior is:
prompt + view + capabilities + output schema + handler
The view is behavior-specific, assembled from graph state under policy. It can include the current event, frame events, sources, observations, tasks, actions, artifacts, memory, agent profile, identity context, channel context, domain context, available capabilities, and policy constraints — but only the parts that behavior is supposed to see.
This is another reason packs beat a central loop. The pack that owns a behavior declares the kind of view that behavior needs; the runtime assembles it from evented graph state; the policy layer filters it; the output schema determines what graph state the behavior may produce. The model operates over a scoped projection, not the assistant's whole hidden world. That's a cleaner safety surface, a cleaner debugging surface, and a cleaner authoring surface at once.
Memory should be candidate-first
Memory is another place where assistant architectures collapse proposal and authority. A model says something seems important, so the system writes it to memory. A summary process extracts a preference, and it becomes durable context. A user says something once, and the assistant later treats it as standing truth. Fine for toys, risky for long-running assistants.
ActiveGraph Core only needs memory_candidate. A memory candidate says: this might be worth remembering. It does not say:
accept this
dedupe this
trust this
retrieve this forever
sync this externally
show this to all future behaviors
Those decisions belong to memory_gateway and policy — the same discipline as the self-modification work, where generated code is not authorized behavior and a self-change proposal is not a promoted change. A possible memory is not durable assistant state yet.
The sequence is evented:
observation created
→ memory_candidate proposed
→ memory evaluation runs
→ accepted / rejected / merged / expired
→ memory item written
→ future behavior view requests memory
→ retrieval event recorded
Memory becomes part of the trace. You can ask why a memory exists — what source produced it, what candidate proposed it, what evaluation accepted it, whether it conflicted with another memory, when it was retrieved, which response used it. That's the difference between "memory as a vector store" and "memory as authorized graph state with retrieval as an event." External systems still help — pgvector, Mem0, Supermemory, local embeddings, keyword search — but they sit behind the gateway as retrieval and indexing backends, not as silent mutators of assistant state. The canonical memory lifecycle stays graph-native.
Tools should become actions, not ambient authority
A useful assistant needs tools, and it needs to not treat tools as ambient authority. A tool call isn't just a function invocation. It's a proposed or executed operation with identity, permission, context, arguments, result, failure mode, cost, side effects, and provenance. That's why Core has action.
A draft email, a calendar write, a web fetch, a repo edit, a CRM update, a command execution, a payment, a deletion — all become action-shaped graph state, with the tool gateway normalizing external capability calls into that lifecycle. The lifecycle varies by risk:
low-risk read action
→ proposed
→ policy allowed
→ executed
→ observation emitted
medium-risk write action
→ proposed
→ evaluation
→ approval required
→ executed or denied
high-risk action
→ proposed
→ blocked / escalated / sandboxed
The point is that authority is visible. A model proposes an action; the system grants authority separately; the execution is logged; the result is graph state; downstream behaviors react to the result, not to a hidden tool return value. It's the same pattern that keeps recurring in ActiveGraph — proposal is state, validation is state, promotion is state, execution is state, result is state — and the log is what lets those distinctions survive.
Bundles are not packs
The repo ships bundles:
assistant
email_assistant
vc_bundle
research_bundle
A bundle exists because nobody wants to load sixteen packs by hand for a demo. But a bundle is a preset load order plus factory defaults — not a third ontology layer.
assistant =
core
tool_gateway
secrets
memory_gateway
agent_profile
identity_auth
communication
chat
email_assistant =
assistant
email
entity
vc_bundle =
email_assistant
diligence_core_bridge
vc
meeting
research_bundle =
core
tool_gateway
memory_gateway
research
Bundles are product-shaped; packs are architecture-shaped. "VC assistant" is a useful product shape, but it shouldn't own a separate ontology that duplicates communication, identity, memory, tools, meetings, and diligence. It assembles packs that already know how to speak Core. The bundle says: load these capabilities together. The packs say: here is the shared state they use to compose.
What building with packs feels like
The developer experience is different from writing a normal workflow. In a normal pipeline you look for the main function. In ActiveGraph the main function is mostly gone.
You define object types and behaviors. A behavior reacts to a local event and writes new graph state. That write may trigger another behavior, possibly in another pack. The runtime drains the cascade:
communication/message created
→ create core/source
core/source created
→ resolve identity_auth/principal
identity_auth/principal created
→ build auth context
auth context created
→ evaluate permissions
permissions evaluated
→ create core/evaluation
Each behavior is small, testable, and has a narrow input and output. The cascade is the program. This feels strange coming from a script or ORM mindset — you keep looking for the place where the whole workflow is written down, and instead it's distributed across typed reactions.
That's the point, and it creates new requirements. You need good trace inspection, because unexpected cascades happen. You need clear schema discipline, because downstream behaviors can only read fields that were actually declared. You need safe graph-access patterns inside behaviors, because full graph scans create re-entrancy problems. You need fixtures, because a pack should be testable without a live LLM key. You need dependency conventions, because optional integrations shouldn't become hidden required imports. You need an Inspector UI, because pack composition is hard to follow if you can't see the objects, relations, events, frames, behaviors, and loaded packs.
These frictions aren't incidental — they're exactly where ActiveGraph needs to get easier to build on. The repo is useful partly because it exposes those seams (I wrote up the rough ones, including the re-entrancy footgun, in the builder report).
What this shows about ActiveGraph
Most agent frameworks start with the model. ActiveGraph starts below it, and packs make that concrete because they stress the runtime the way real assistants will. A single demo can hide architectural problems; a multi-pack assistant exposes them.
If the substrate is wrong, packs become a tangle: domain packs call each other directly, tool calls bypass policy, memory becomes a side channel, identity becomes a prompt string, UI traces become hand-built reconstructions, integrations become required dependencies, and the system only works when every part knows every other part. The pack model forces a better discipline:
- Everything important becomes typed state. Messages, sources, observations, tasks, actions, artifacts, evaluations, memory candidates, principals, entities, drafts, memos, claims, risks, and tool calls are objects and relations, not text in a transcript.
- Every transition is evented. A pack doesn't ask another pack to run; it writes graph state, the runtime records the mutation, and other behaviors react. The trace is native, not reconstructed.
- Context is assembled from graph views. Each behavior sees the scoped view it needs, under policy, with provenance — no global prompt blob.
- Capabilities add without rewiring. A new pack listens for Core or domain objects and emits its own outputs; if it maps back to Core, infrastructure packs participate immediately.
- UIs are projections. The Inspector UI is a window onto the graph and log, not the assistant. A different UI could show an inbox, a diligence cockpit, a memory review queue, a tool audit log, or a fork tree. The event log stays canonical.
- AI can build against it. The pack structure gives an AI builder explicit files, schemas, fixtures, README conventions, dependency declarations, and behavior maps. The repo isn't only for humans reading code — it's training material for coding agents that need to author packs correctly.
That last point matters for the broader direction. If the goal is a system that can help extend itself, the extension surface has to be legible. A generated behavior draft is one unit of authority; a pack is a larger one — vocabulary, behaviors, tools, prompts, fixtures, and docs. Eventually I want an agent to read the existing conventions, propose a new pack, run fixtures, inspect graph diffs, and ask for promotion. That's far easier when the unit of extension is structured and event-sourced from the start.
A concrete VC assistant path
The VC bundle is the most natural first complete assistant for me, because it maps to a workflow I actually run.
A founder email comes in. The email pack creates the email objects and a Core source. The communication pack extracts the message and candidate intent. The identity pack resolves who sent it and what authority they have. The entity pack connects sender, company, fund, prior interactions, and portfolio relationships. The memory gateway retrieves relevant prior context — past meetings, relationship notes, decisions, preferences, intros, followups. The VC pack creates company, founder, and deal observations. The diligence bridge maps deeper diligence outputs back to Core observations, artifacts, and evaluations. The meeting pack attaches meeting context or creates follow-up tasks. The email pack formats a draft. The tool gateway proposes actions: send reply, label email, create follow-up, schedule meeting, update CRM.
The user sees a draft. The graph contains the actual work:
source: inbound email
observation: founder is raising pre-seed
observation: company matches prior thesis
observation: prior intro from trusted relationship
memory_candidate: founder prefers concise tactical feedback
task: draft reply
action: retrieve prior company context
artifact: response candidate
evaluation: requires human approval before send
action: send email if approved
This is what I want from an assistant — not just "write a reply," but a record of what it saw, what it remembered, what it inferred, what it proposed, what it executed, and what it decided not to do. I want to fork the run before the draft and compare two reply strategies. I want to inspect which memory affected the response. I want to add a behavior that flags conflict of interest, and a policy that prevents outreach to LPs without approval. I want meeting notes to create tasks without the meeting pack knowing how email works. That's a substrate problem, not a prompt problem.
What this does and does not claim
The claim is narrow. activegraph-packs is a reference implementation of a composition model for ActiveGraph packs. It shows how a small Core vocabulary, layered packs, optional integrations, deterministic fixtures, bridges, bundles, a demo server, and an Inspector UI can make a multi-pack assistant legible.
It does not claim to be a finished personal assistant, that the current pack set is the final ontology, that event sourcing solves every safety problem, that every domain should be represented through these exact objects, or that any of this is production multi-tenant ready.
The useful claim is architectural. If long-running assistants are going to communicate, remember, use tools, act externally, specialize by domain, and improve over time, their capabilities need a compositional substrate. A central coordinator gets surprisingly far, then becomes the wrong abstraction the moment you want auditability, replay, fork, behavior-local context, memory governance, identity, policy, and independently authored capabilities. ActiveGraph already has the lower-level primitives — event log, graph, objects, relations, behaviors, tools, forks, diffs, projections. Packs are the next layer up, and they make the extension surface visible.
Where this sits
The ActiveGraph blog has been circling the same idea from different angles. The Log is the Agent argued the event log should be the source of truth and the graph a projection of it. The LongMemEval work tested whether that substrate could support memory and evidence compilation without becoming an obvious retrieval tax. The semantic memory posts showed why memory should compile back to source evidence rather than replace it. selfgraph showed bounded graph-native self-change: proposed patches, forks, diffs, promotion, replay. BehaviorDrafts widened the action space to generated behavior source while keeping a promotion boundary between authorship and runtime authority. Regimes added an auditable held-out gate on top of that loop. AG Coder rebuilt a familiar agent workflow on the substrate. Deep Research made provenance the product.
Packs are the composition step. They're how one runtime can support a personal assistant, research assistant, coding assistant, VC assistant, team-ops assistant, and future domain packs without each one reinventing memory, identity, communication, tools, and policy. The interesting result isn't that there are fifteen packs — it's that they share a seven-object Core without becoming one giant ontology, and coordinate through graph-visible state without a central coordinator.
What I want this repo to become
Three things.
A working reference for humans. If you want to build on ActiveGraph, you should be able to read the repo and see how to define object types, write behaviors, expose tools, create fixtures, document dependencies, map domain outputs back to Core, and compose packs into a bundle.
A target for AI builders. A coding agent should be able to read the pack conventions and author a new pack that fits — knowing where schemas go, where behaviors go, how fixtures work, how prompts are declared, how dependencies are documented, and how outputs map back to Core.
A path toward self-extending assistants. The longer-term direction isn't "more packs." It's an assistant that notices a missing capability, proposes a pack or behavior draft, runs it in a fork, inspects the graph effects, generates fixtures, asks for promotion, and then carries the new capability into its future operating surface. That needs the same discipline as the rest of ActiveGraph: authorship is not authority, a proposed behavior is not a live behavior, a memory candidate is not durable memory, a bundle is not an ontology, a domain object is not automatically Core, a tool call is not ambient permission, and a response is not just text — it's an artifact with lineage. Packs give those distinctions a concrete place to live.
Code and artifacts
The repo is open source under Apache 2.0:
github.com/yoheinakajima/activegraph-packs
It includes the pack library, the four bundles, deterministic fixtures, a Python demo server, and a React Inspector UI. The same code runs three ways with no API key: use the packs directly in Python, run the standalone demo server, or bring up the full UI / API / runtime stack locally.
The point isn't to be the definitive assistant. It's to make the assistant substrate concrete enough that people — and AI — can build on it.
ActiveGraph is easiest to understand when you stop looking for the loop. The loop isn't gone; it's distributed into behaviors over replayable graph state. Packs are how that distribution becomes composable.
← back to blog